Download this notebook from github.
Workflow Examples¶
xclim is built on very powerful multiprocessing and distributed computation libraries, notably xarray and dask.
xarray is a python package making it easy to work with n-dimensional arrays. It labels axes with their names [time, lat, lon, level] instead of indices [0,1,2,3], reducing the likelihood of bugs and making the code easier to understand. One of the key strengths of xarray is that it knows how to deal with non-standard calendars (we’re looking at you, “360_days”) and can easily resample daily time series to weekly, monthly, seasonal or annual periods. Finally, xarray is
tightly integrated with dask, a package that can automatically parallelize operations.
The following are a few examples to consult when using xclim to subset NetCDF arrays and compute climate indicators, taking advantage of the parallel processing capabilities offered by xarray and dask. For more information about these projects, please see their documentation pages:
Environment configuration¶
[1]:
import tempfile
from pathlib import Path
import xarray as xr
import xclim.indices
# Set xarray to use HTML for displaying outputs
xr.set_options(display_style="html")
# Output folder
output_folder = Path(tempfile.mkdtemp())
Setting up the Dask client: parallel processing¶
In this example, we are using the **dask.distributed** submodule. This is not installed by default in a basic xclim installation. Be sure to add distributed to your Python installation before setting up parallel processing operations!
First, we create a pool of workers that will wait for jobs. The xarray library will automatically connect to these workers and dispatch them jobs that can be run in parallel.
The dashboard link lets you see in real time how busy those workers are.
This step is not mandatory, as dask will fall back to its “single machine scheduler” if a Client is not created. However, this default scheduler doesn’t allow you to set the number of threads or a memory limit and doesn’t start the dashboard, which can be quite useful to understand your task’s progress.
[2]:
from distributed import Client
# Depending on your workstation specifications, you may need to adjust these values.
# On a single machine, n_workers=1 is usually better.
client = Client(n_workers=1, threads_per_worker=4, memory_limit="4GB")
client
INFO:distributed.http.proxy:To route to workers diagnostics web server please install jupyter-server-proxy: python -m pip install jupyter-server-proxy
INFO:distributed.scheduler:State start
INFO:distributed.diskutils:Found stale lock file and directory '/tmp/dask-scratch-space/scheduler-uw7b61yk', purging
INFO:distributed.scheduler: Scheduler at: tcp://127.0.0.1:39493
INFO:distributed.scheduler: dashboard at: http://127.0.0.1:8787/status
INFO:distributed.scheduler:Registering Worker plugin shuffle
INFO:distributed.nanny: Start Nanny at: 'tcp://127.0.0.1:45009'
INFO:distributed.scheduler:Register worker addr: tcp://127.0.0.1:37699 name: 0
INFO:distributed.scheduler:Starting worker compute stream, tcp://127.0.0.1:37699
INFO:distributed.core:Starting established connection to tcp://127.0.0.1:45124
INFO:distributed.scheduler:Receive client connection: Client-7f0ea87e-5857-11f1-929d-2221dfaedb87
INFO:distributed.core:Starting established connection to tcp://127.0.0.1:45140
[2]:
Client
Client-7f0ea87e-5857-11f1-929d-2221dfaedb87
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: http://127.0.0.1:8787/status |
Cluster Info
LocalCluster
bbdad743
| Dashboard: http://127.0.0.1:8787/status | Workers: 1 |
| Total threads: 4 | Total memory: 3.73 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-98f77021-9891-4fa8-b3c9-1a17ea4520b2
| Comm: tcp://127.0.0.1:39493 | Workers: 0 |
| Dashboard: http://127.0.0.1:8787/status | Total threads: 0 |
| Started: Just now | Total memory: 0 B |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:37699 | Total threads: 4 |
| Dashboard: http://127.0.0.1:37755/status | Memory: 3.73 GiB |
| Nanny: tcp://127.0.0.1:45009 | |
| Local directory: /tmp/dask-scratch-space/worker-n2n15ivq | |
Creating xarray datasets¶
To open a NetCDF file with xarray, we use xr.open_dataset(<path to file>). By default, the entire file is stored in one chunk, so there is no parallelism. To trigger parallel computations, we need to explicitly specify the chunk size.
In this example, instead of opening a local file, we pass an OPeNDAP URL to xarray. It retrieves the data automatically. Notice also that opening the dataset is quite fast. In fact, the data itself has not been downloaded yet, only the coordinates and the metadata. The downloads will be triggered only when the values need to be accessed directly.
dask’s parallelism is based on memory chunks; We need to tell xarray to split our NetCDF array into chunks of a given size, and operations on each chunk of the array will automatically be dispatched to the workers.
[3]:
data_url = "https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/datasets/simulations/bias_adjusted/cmip6/ouranos/ESPO-G/ESPO-G6-E5Lv1.0.0/day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CSIRO_ACCESS-ESM1-5_ssp370_r1i1p1f1_1950-2100.ncml"
[4]:
# Chunking in memory along the time dimension.
# Note that the data type is a 'dask.array'. xarray will automatically use client workers.
ds = xr.open_dataset(
data_url,
chunks={"time": 1460, "lat": 50, "lon": 50},
engine="netcdf4",
)
ds
[4]:
<xarray.Dataset> Size: 825GB
Dimensions: (time: 55115, lat: 734, lon: 1700)
Coordinates:
* time (time) object 441kB 1950-01-01 00:00:00 ... 2100-12-31 00:00:00
* lat (lat) float32 3kB 10.0 10.1 10.2 10.3 10.4 ... 83.0 83.1 83.2 83.3
* lon (lon) float32 7kB -179.9 -179.8 -179.7 -179.6 ... -10.2 -10.1 -10.0
Data variables:
tasmin (time, lat, lon) float32 275GB dask.array<chunksize=(1460, 50, 50), meta=np.ndarray>
tasmax (time, lat, lon) float32 275GB dask.array<chunksize=(1460, 50, 50), meta=np.ndarray>
pr (time, lat, lon) float32 275GB dask.array<chunksize=(1460, 50, 50), meta=np.ndarray>
Attributes: (12/84)
Conventions: CF-1.7 CMIP-6.2
Notes: Regridded on the grid of ERA5-Land, then...
activity_id: CMIP
branch_method: standard
branch_time_in_child: 0.0
branch_time_in_parent: 21915.0
... ...
bias_adjust_reference_citation: https://doi.org/10.24381/cds.e2161bac
license_type: permissive
terms_of_use: In addition to the provided licence, the...
attribution: Use of this dataset should be acknowledg...
modeling_realm: atmos
source_institution: CSIRO[5]:
print(ds.tasmin.chunks)
((1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1460, 1095), (50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 34), (50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50))
Multi-file datasets¶
NetCDF files are often split into periods to keep file size manageable. A single dataset can be split in dozens of individual files. xarray has a function open_mfdataset that can open and aggregate a list of files and construct a unique logical dataset. open_mfdataset can aggregate files over coordinates (time, lat, lon) and variables.
Note that opening a multi-file dataset automatically chunks the array (one chunk per file).
Note also that because
xarrayreads every file metadata to place it in a logical order, it can take a while to load.
[6]:
# Create multi-file data & chunks
# ds = xr.open_mfdataset('/path/to/files*.nc')
Subsetting and selecting data with xarray¶
Here, we will reduce the size of our data using the methods implemented in xarray (docs here).
[7]:
ds2 = ds.sel(lat=slice(50, 45), lon=slice(-70, -65), time=slice("2090", "2100"))
ds2.tasmin
[7]:
<xarray.DataArray 'tasmin' (time: 4015, lat: 0, lon: 51)> Size: 0B
dask.array<getitem, shape=(4015, 0, 51), dtype=float32, chunksize=(1460, 0, 50), chunktype=numpy.ndarray>
Coordinates:
* time (time) object 32kB 2090-01-01 00:00:00 ... 2100-12-31 00:00:00
* lat (lat) float32 0B
* lon (lon) float32 204B -70.0 -69.9 -69.8 -69.7 ... -65.2 -65.1 -65.0
Attributes:
long_name: Minimal daily temperature
cell_methods: time: minimum within days
description: Daily minimal temperature as...
history: [2024-11-08 04:09:23] Data c...
standard_name: air_temperature
units: K
_QuantizeBitRoundNumberOfSignificantDigits: 12
_ChunkSizes: [1460 50 50][8]:
ds3 = ds.sel(lat=46.8, lon=-71.22, method="nearest").sel(time="1993")
ds3.tasmin
[8]:
<xarray.DataArray 'tasmin' (time: 365)> Size: 1kB
dask.array<getitem, shape=(365,), dtype=float32, chunksize=(365,), chunktype=numpy.ndarray>
Coordinates:
* time (time) object 3kB 1993-01-01 00:00:00 ... 1993-12-31 00:00:00
lat float32 4B 46.8
lon float32 4B -71.2
Attributes:
long_name: Minimal daily temperature
cell_methods: time: minimum within days
description: Daily minimal temperature as...
history: [2024-11-08 04:09:23] Data c...
standard_name: air_temperature
units: K
_QuantizeBitRoundNumberOfSignificantDigits: 12
_ChunkSizes: [1460 50 50]For more powerful subsetting tools with features such as coordinate reference system (CRS) aware subsetting and vector shape masking, the xclim developers strongly encourage users to consider the subsetting utilities of the clisops package.
Their documentation showcases several examples of how to perform more complex subsetting: clisops.core.subset.
Climate index calculation & resampling frequencies¶
xclim has two layers for the calculation of indicators. The bottom layer is composed of a list of functions that take one or more xarray.DataArray’s as input and return an xarray.DataArray as output. You’ll find these functions in xclim.indices. The indicator’s logic is contained in this function, as well as some unit handling, but it doesn’t perform any data consistency checks (like if the time frequency is daily), and doesn’t adjust the metadata of the output array.
The second layer are class instances that you’ll find organized by realm. So far, there are three realms available in xclim.atmos, xclim.seaIce and xclim.land, the first one being the most exhaustive. Before running computations, these classes check if the input data is a daily average of the expected variable:
If an indicator expects a daily mean, and you pass it a daily max, a
warningwill be raised.After the computation, it also checks the number of values per period to make sure there are not missing values or
NaNin the input data. If there are, the output is going to be set toNaN. Ex. : If the indicator performs a yearly resampling, but there are only 350 non-NaNvalues in one given year in the input data, that year’s output will beNaN.The output units are set correctly as well as other properties of the output array, complying as much as possible with CF conventions.
For new users, we suggest you use the classes found in xclim.atmos and others. If you know what you’re doing, and you want to circumvent the built-in checks, then you can use the xclim.indices directly.
Almost all xclim indicators convert daily data to lower time frequencies, such as seasonal or annual values. This is done using xarray.DataArray.resample method. Resampling creates a grouped object over which you apply a reduction operation (e.g. mean, min, max). The list of available frequency is given in the link below, but the most often used are:
YS: annual starting in JanuaryYS-JUL: annual starting in JulyMS: monthlyQS-DEC: seasonal starting in December
More info about this specification can be found in pandas’ documentation
Note - not all offsets in the link are supported by cftime objects in xarray.
In the example below, we’re computing the annual maximum temperature of the daily maximum temperature (tx_max).
[9]:
out = xclim.atmos.tx_max(ds2.tasmax, freq="YS")
out
[9]:
<xarray.DataArray 'tx_max' (time: 11, lat: 0, lon: 51)> Size: 0B
dask.array<where, shape=(11, 0, 51), dtype=float32, chunksize=(4, 0, 50), chunktype=numpy.ndarray>
Coordinates:
* time (time) object 88B 2090-01-01 00:00:00 ... 2100-01-01 00:00:00
* lat (lat) float32 0B
* lon (lon) float32 204B -70.0 -69.9 -69.8 -69.7 ... -65.2 -65.1 -65.0
Attributes:
long_name: Maximum daily maximum temper...
bias_adjustment: DetrendedQuantileMapping(gro...
cell_measures: area: areacella
cell_methods: time: maximum within days ti...
comment: maximum near-surface (usuall...
history: [2026-05-25 16:33:45] tx_max...
standard_name: air_temperature
units: K
_QuantizeBitRoundNumberOfSignificantDigits: 12
_ChunkSizes: [1460 50 50]
units_metadata: temperature: unknown
description: Annual maximum of daily maxi...If you execute the cell above, you’ll see that this operation is quite fast. This a feature coming from dask. Read Lazy computation further down.
Comparison of atmos vs indices modules¶
Using the xclim.indices module performs not checks and only fills the units attribute.
[10]:
out = xclim.indices.tx_days_above(ds2.tasmax, thresh="30 degC", freq="YS")
out
[10]:
<xarray.DataArray 'tasmax' (time: 11, lat: 0, lon: 51)> Size: 0B
dask.array<mul, shape=(11, 0, 51), dtype=int64, chunksize=(4, 0, 50), chunktype=numpy.ndarray>
Coordinates:
* time (time) object 88B 2090-01-01 00:00:00 ... 2100-01-01 00:00:00
* lat (lat) float32 0B
* lon (lon) float32 204B -70.0 -69.9 -69.8 -69.7 ... -65.2 -65.1 -65.0
Attributes:
long_name: Maximal daily temperature
bias_adjustment: DetrendedQuantileMapping(gro...
cell_measures: area: areacella
cell_methods: time: maximum within days
comment: maximum near-surface (usuall...
history: [2024-11-08 04:33:13] Data c...
standard_name: air_temperature
units: d
_QuantizeBitRoundNumberOfSignificantDigits: 12
_ChunkSizes: [1460 50 50]With xclim.atmos, checks are performed and many CF-compliant attributes are added:
[11]:
out = xclim.atmos.tx_days_above(ds2.tasmax, thresh="30 degC", freq="YS")
out
[11]:
<xarray.DataArray 'tx_days_above' (time: 11, lat: 0, lon: 51)> Size: 0B
dask.array<where, shape=(11, 0, 51), dtype=float64, chunksize=(4, 0, 50), chunktype=numpy.ndarray>
Coordinates:
* time (time) object 88B 2090-01-01 00:00:00 ... 2100-01-01 00:00:00
* lat (lat) float32 0B
* lon (lon) float32 204B -70.0 -69.9 -69.8 -69.7 ... -65.2 -65.1 -65.0
Attributes:
long_name: The number of days with maxi...
bias_adjustment: DetrendedQuantileMapping(gro...
cell_measures: area: areacella
cell_methods: time: maximum within days ti...
comment: maximum near-surface (usuall...
history: [2026-05-25 16:33:46] tx_day...
standard_name: number_of_days_with_air_temp...
units: days
_QuantizeBitRoundNumberOfSignificantDigits: 12
_ChunkSizes: [1460 50 50]
description: Annual number of days where ...[12]:
# We have created an xarray data-array.
# We can insert this into an output xr.Dataset object with a copy of the original dataset global attrs
ds_out = xr.Dataset(attrs=ds2.attrs)
# Add our climate index as a data variable to the dataset
ds_out[out.name] = out
ds_out
[12]:
<xarray.Dataset> Size: 292B
Dimensions: (lat: 0, lon: 51, time: 11)
Coordinates:
* lat (lat) float32 0B
* lon (lon) float32 204B -70.0 -69.9 -69.8 ... -65.2 -65.1 -65.0
* time (time) object 88B 2090-01-01 00:00:00 ... 2100-01-01 00:00:00
Data variables:
tx_days_above (time, lat, lon) float64 0B dask.array<chunksize=(4, 0, 1), meta=np.ndarray>
Attributes: (12/84)
Conventions: CF-1.7 CMIP-6.2
Notes: Regridded on the grid of ERA5-Land, then...
activity_id: CMIP
branch_method: standard
branch_time_in_child: 0.0
branch_time_in_parent: 21915.0
... ...
bias_adjust_reference_citation: https://doi.org/10.24381/cds.e2161bac
license_type: permissive
terms_of_use: In addition to the provided licence, the...
attribution: Use of this dataset should be acknowledg...
modeling_realm: atmos
source_institution: CSIRODifferent ways of resampling¶
Many indices use algorithms that find the length of given sequences. For instance, xclim.indices.heat_wave_max_length finds the longest sequence where tasmax and tasmin are above given threshold values. Resampling can be used to find the longest sequence in given periods of time, for instance the longest heat wave for each month if the resampling frequency is freq == "MS".
The order of the two operations just described, i.e. :
Finding the length of sequences respecting a certain criterion (“run length algorithms”)
Separating the dataset in given time periods (“resampling”)
is important and can lead to differing results.
The cell below illustrates this by looking at the maximum lengths of heat waves each month from May 2010 to August 2010 by doing these operations in the two possible orders. The heat wave max lengths for July in a small region of interest \(\text{lat} \in [43, 44.5],\, \text{lon} \in [-117.5, -116]\) are shown: The maximal lengths are sometimes longer first applying the run length algorithm (resample_before_rl == False).
[13]:
# import plotting stuff
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams["figure.figsize"] = (11, 5)
[14]:
ds_reduced = ds.sel(lat=slice(43, 44.5)).sel(lon=slice(-117.5, -116)).sel(time=slice("2010-05-01", "2011-08-31"))
tn, tx = ds_reduced.tasmin, ds_reduced.tasmax
freq = "MS"
# Threshold on tasmin: chosen smaller than the default 22.0 degC
thresh_tn = "20.0 degC"
# Computing index by resampling **before** run length algorithm (default value)
hw_before = xclim.indices.heat_wave_max_length(tn, tx, freq=freq, thresh_tasmin=thresh_tn, resample_before_rl=True)
# Computing index by resampling **after** run length algorithm
hw_after = xclim.indices.heat_wave_max_length(tn, tx, freq=freq, thresh_tasmin=thresh_tn, resample_before_rl=False)
hw_before.sel(time="2010-07-01").plot(vmin=0, vmax=7)
plt.title("Resample, then run length")
plt.figure()
hw_after.sel(time="2010-07-01").plot(vmin=0, vmax=7)
plt.title("Run length, then resample")
plt.show()
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 1:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/datasets/simulations/bias_adjusted/cmip6/ouranos/ESPO-G/ESPO-G6-E5Lv1.0.0/day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CSIRO_ACCESS-ESM1-5_ssp370_r1i1p1f1_1950-2100.ncml', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 1:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'tmp_1025', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 2:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/datasets/simulations/bias_adjusted/cmip6/ouranos/ESPO-G/ESPO-G6-E5Lv1.0.0/day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CSIRO_ACCESS-ESM1-5_ssp370_r1i1p1f1_1950-2100.ncml', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 2:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'tmp_1027', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
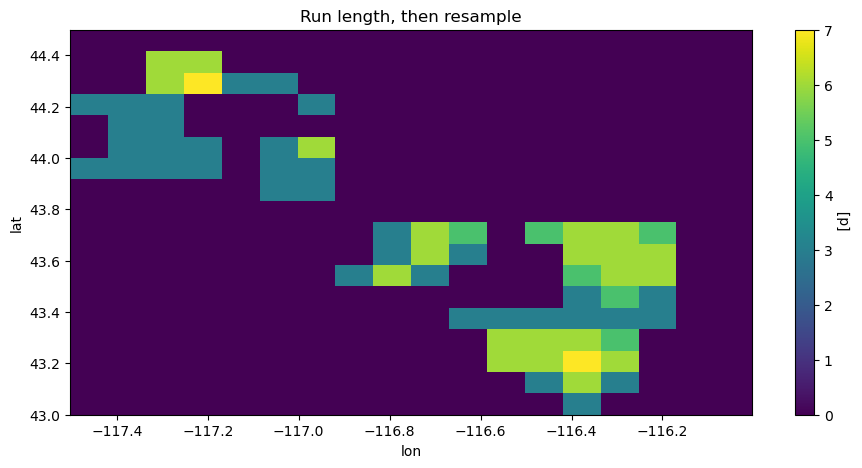

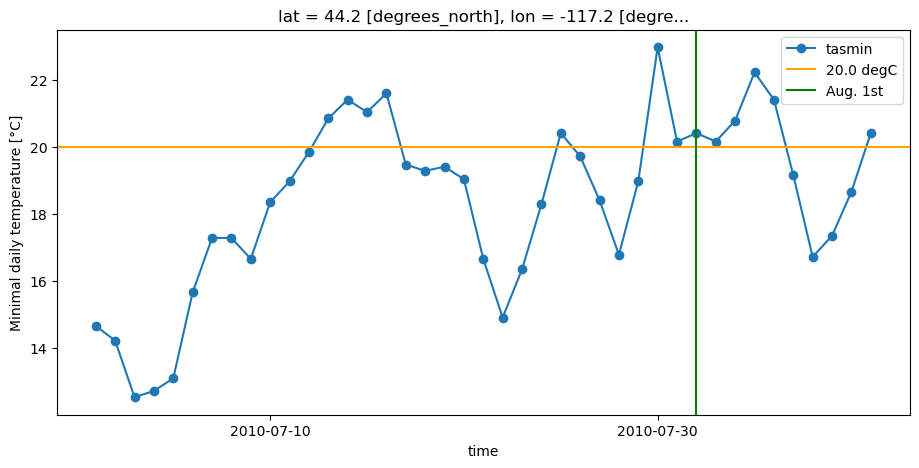
Let’s focus on the point \((-117.2, 44.2)\), which has a maximum wave length of five (5) or seven (7), depending on whether resampling occurs before or after the run length algorithm.
Plotting the values of tasmin in July and early August, we see a sequence of seven hot minimal temperatures at the end of July that surpass the threshold to qualify for a heat wave.
If resampling occurs first, and we first separate the periods in months, the run length algorithms will only look for sequences of hot days within the month of July and will exclude the last three days of this sequence of seven days.
Using the run length algorithm before resampling looks for sequences of hot days in all the dataset given (temperatures from May 1, 2010, to August 31, 2010), and then subdivides these sequences in the months when they have started. Since it starts in July, this sequence is registered as counts for a heat wave of seven days happening in July.
This also implies that the first three days of August which belong in this sequence of seven days will be counted as a sequence in August with the first method, but not with the second.
[15]:
import cftime
from xclim.core.units import convert_units_to
# Select a spatial point of interest in July-early August
lon_i, lat_i = -117.2, 44.2
tn_pt = tn.sel(time=slice("2010-07-01", "2010-08-10")).sel(lat=lat_i, lon=lon_i, method="nearest")
tn_pt = convert_units_to(tn_pt, "degC")
# Find August 1st threshold value
aug1 = cftime.datetime(2010, 8, 1, calendar="noleap")
tn_pt.plot(marker="o", label="tasmin")
plt.axhline(y=convert_units_to(thresh_tn, "degC"), color="orange", label=thresh_tn)
plt.axvline(x=aug1, color="green", label="Aug. 1st")
plt.legend()
plt.show()
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 3:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/datasets/simulations/bias_adjusted/cmip6/ouranos/ESPO-G/ESPO-G6-E5Lv1.0.0/day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CSIRO_ACCESS-ESM1-5_ssp370_r1i1p1f1_1950-2100.ncml', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 3:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'tmp_1029', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
Lazy computation - Nothing has been computed so far !¶
If you look at the output of those operations, they’re identified as dask.array objects. What happens is that dask creates a chain of operations that, when executed, will yield the values we want. We have thus far only created a schedule of tasks with a small preview and not done any actual computations, except when making figures. You can trigger computations by using the load or compute method, or writing the output to disk via to_netcdf. Of course, calling .plot() will
also trigger the computation.
[16]:
%%time
output_file = output_folder / "test_tx_max.nc"
ds_out.to_netcdf(output_file)
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 3:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/datasets/simulations/bias_adjusted/cmip6/ouranos/ESPO-G/ESPO-G6-E5Lv1.0.0/day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CSIRO_ACCESS-ESM1-5_ssp370_r1i1p1f1_1950-2100.ncml', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 3:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'tmp_1031', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
CPU times: user 89.8 ms, sys: 13.2 ms, total: 103 ms
Wall time: 592 ms
(Times may of course vary depending on the machine and the Client settings)
Performance tips¶
Optimizing the chunk size¶
You can improve performance by being smart about chunk sizes. If chunks are too small, there is a lot of time lost in overhead. If chunks are too large, you may end up exceeding the individual worker memory limit.
[17]:
print(ds2.chunks["time"])
(1460, 1460, 1095)
[18]:
# rechunk data in memory for the entire grid
ds2c = ds2.chunk(chunks={"time": 4 * 365})
print(ds2c.chunks["time"])
(1460, 1460, 1095)
[19]:
%%time
out = xclim.atmos.tx_max(ds2c.tasmax, freq="YS")
ds_out = xr.Dataset(data_vars=None, coords=out.coords, attrs=ds.attrs)
ds_out[out.name] = out
output_file = output_folder / "test_tx_max.nc"
ds_out.to_netcdf(output_file)
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 4:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/datasets/simulations/bias_adjusted/cmip6/ouranos/ESPO-G/ESPO-G6-E5Lv1.0.0/day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CSIRO_ACCESS-ESM1-5_ssp370_r1i1p1f1_1950-2100.ncml', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 4:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'tmp_1033', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
CPU times: user 193 ms, sys: 15.1 ms, total: 208 ms
Wall time: 3.05 s
Loading the data in memory¶
If the dataset is relatively small, it might be more efficient to simply load the data into the memory and use numpy arrays instead of dask arrays.
[20]:
ds4 = ds3.load()
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 4:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/datasets/simulations/bias_adjusted/cmip6/ouranos/ESPO-G/ESPO-G6-E5Lv1.0.0/day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CSIRO_ACCESS-ESM1-5_ssp370_r1i1p1f1_1950-2100.ncml', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 4:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'tmp_1035', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
Unit handling in xclim¶
A lot of effort has been placed into automatic handling of input data units. xclim will automatically detect the input variable(s) units (e.g. °C versus °K or mm/s versus mm/day etc.) and adjust on-the-fly in order to calculate indices in the consistent manner. This comes with the obvious caveat that input data requires metadata attribute for units.
The Units Handling page goes more into detail on how unit conversion can easily be done.
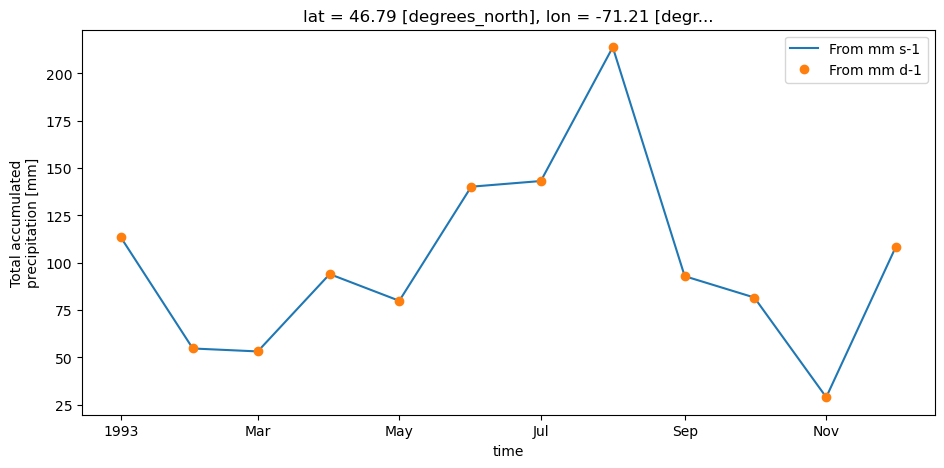
In the example below, we compute weekly total precipitation in mm using inputs of mm/s and mm/d. As we can see, the output is identical.
[21]:
# Compute with the original mm s-1 data
out1 = xclim.atmos.precip_accumulation(ds4.pr, freq="MS")
# Create a copy of the data converted to mm d-1
pr_mmd = ds4.pr * 3600 * 24
pr_mmd.attrs["units"] = "mm d-1"
out2 = xclim.atmos.precip_accumulation(pr_mmd, freq="MS")
[22]:
plt.figure()
out1.plot(label="From mm s-1", linestyle="-")
out2.plot(label="From mm d-1", linestyle="none", marker="o")
plt.legend()
plt.show()
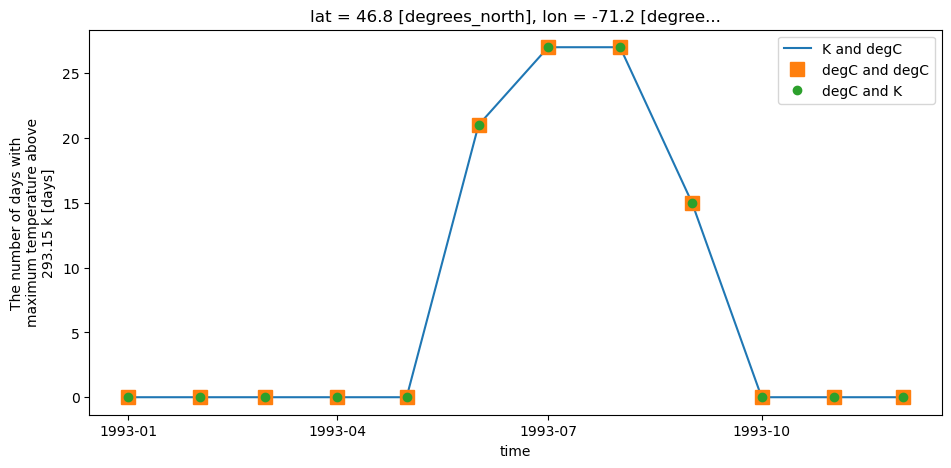
Threshold indices¶
xclim unit handling also applies to threshold indicators. Users can provide threshold in units of choice and xclim will adjust automatically. For example, determining the number of days with tasmax > 20 °C, users can define a threshold input of "20 C" or "20 degC" even if input data is in Kelvin. Alternatively, users can even provide a threshold in Kelvin ("293.15 K", if they really wanted to).
[23]:
# Create a copy of the data converted to C
tasmax_C = ds4.tasmax - 273.15
tasmax_C.attrs["units"] = "C"
# Using Kelvin data, threshold in Celsius
out1 = xclim.atmos.tx_days_above(ds4.tasmax, thresh="20 C", freq="MS")
# Using Celsius data
out2 = xclim.atmos.tx_days_above(tasmax_C, thresh="20 C", freq="MS")
# Using Celsius but with threshold in Kelvin
out3 = xclim.atmos.tx_days_above(tasmax_C, thresh="293.15 K", freq="MS")
# Plot and see that it's all identical:
plt.figure()
out1.plot(label="K and degC", linestyle="-")
out2.plot(label="degC and degC", marker="s", markersize=10, linestyle="none")
out3.plot(label="degC and K", marker="o", linestyle="none")
plt.legend()
plt.show()
Spatially varying thresholds¶
Thresholds can also be passed as DataArrays instead of single scalar values, allowing the computation to depend on one or more non-temporal dimensions. The units attribute must be set.
Going back to the initial ds, we’ll subset it and compute the length of the heat wave according to thresholds that vary along the latitude and longitude.
[24]:
ds5 = ds.sel(time=slice("1950", "1960"), lat=slice(46, 50), lon=slice(-75, -71))
ds5
[24]:
<xarray.Dataset> Size: 81MB
Dimensions: (time: 4015, lat: 41, lon: 41)
Coordinates:
* time (time) object 32kB 1950-01-01 00:00:00 ... 1960-12-31 00:00:00
* lat (lat) float32 164B 46.0 46.1 46.2 46.3 46.4 ... 49.7 49.8 49.9 50.0
* lon (lon) float32 164B -75.0 -74.9 -74.8 -74.7 ... -71.2 -71.1 -71.0
Data variables:
tasmin (time, lat, lon) float32 27MB dask.array<chunksize=(1460, 40, 1), meta=np.ndarray>
tasmax (time, lat, lon) float32 27MB dask.array<chunksize=(1460, 40, 1), meta=np.ndarray>
pr (time, lat, lon) float32 27MB dask.array<chunksize=(1460, 40, 1), meta=np.ndarray>
Attributes: (12/84)
Conventions: CF-1.7 CMIP-6.2
Notes: Regridded on the grid of ERA5-Land, then...
activity_id: CMIP
branch_method: standard
branch_time_in_child: 0.0
branch_time_in_parent: 21915.0
... ...
bias_adjust_reference_citation: https://doi.org/10.24381/cds.e2161bac
license_type: permissive
terms_of_use: In addition to the provided licence, the...
attribution: Use of this dataset should be acknowledg...
modeling_realm: atmos
source_institution: CSIRO[25]:
# The tasmin threshold is 7°C for the northern half of the domain and 11°C for the southern half.
# (notice that the lat coordinate is in decreasing order : from north to south)
thresh_tasmin = xr.DataArray([7] * 20 + [11] * 21, dims=("lat",), coords={"lat": ds5.lat}, attrs={"units": "°C"})
# The tasmax threshold is 17°C for the western half of the domain and 21°C for the eastern half.
thresh_tasmax = xr.DataArray([17] * 20 + [21] * 21, dims=("lon",), coords={"lon": ds5.lon}, attrs={"units": "°C"})
out_hw2d = xclim.atmos.heat_wave_total_length(
tasmin=ds5.tasmin,
tasmax=ds5.tasmax,
thresh_tasmin=thresh_tasmin,
thresh_tasmax=thresh_tasmax,
freq="YS",
window=3,
)
The final map for year 1958, shows clear jumps across the 4 quadrants, which was expected with our space-dependent thresholds. Notice also how the long_name (printed on the colorbar label) mentions that the threshold comes from “an array”. This imprecise metadata is a consequence of using DataArray-derived thresholds.
[26]:
out_hw2d.sel(time="1958").plot()
plt.show()
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 1:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/datasets/simulations/bias_adjusted/cmip6/ouranos/ESPO-G/ESPO-G6-E5Lv1.0.0/day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CSIRO_ACCESS-ESM1-5_ssp370_r1i1p1f1_1950-2100.ncml', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file
HDF5-DIAG: Error detected in HDF5 (1.14.6) thread 1:
#000: H5F.c line 496 in H5Fis_accessible(): unable to determine if file is accessible as HDF5
major: File accessibility
minor: Not an HDF5 file
#001: H5VLcallback.c line 3913 in H5VL_file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#002: H5VLcallback.c line 3848 in H5VL__file_specific(): file specific failed
major: Virtual Object Layer
minor: Can't operate on object
#003: H5VLnative_file.c line 344 in H5VL__native_file_specific(): error in HDF5 file check
major: File accessibility
minor: Can't get value
#004: H5Fint.c line 1055 in H5F__is_hdf5(): unable to open file
major: File accessibility
minor: Unable to initialize object
#005: H5FD.c line 787 in H5FD_open(): can't open file
major: Virtual File Layer
minor: Unable to open file
#006: H5FDsec2.c line 323 in H5FD__sec2_open(): unable to open file: name = 'tmp_1037', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0
major: File accessibility
minor: Unable to open file

Hemisphere varying thresholds¶
Some indicators should be computed with different parameters for the north and the south hemisphere. For example, if we want to compute the number of frost days during the winter months. In the northern hemisphere we set the end of a full winter year to July, in the southern hemisphere to December, this changes the resampling frequency.
[27]:
freq_nh = "YS-JUL"
freq_sh = "YS"
Creating a fake dataset, we’ll select the northern and southern hemispheres and compute the number of frost days during the winter month separately.
[28]:
ds6 = xr.concat([ds.sel(lat=67), ds.sel(lat=67)], xr.DataArray([-67, 67], dims=("lat",))).sel(
lon=-179, time=slice("1950", "1951")
)
ds6
[28]:
<xarray.Dataset> Size: 23kB
Dimensions: (lat: 2, time: 730)
Coordinates:
* lat (lat) int64 16B -67 67
* time (time) object 6kB 1950-01-01 00:00:00 ... 1951-12-31 00:00:00
lon float32 4B -179.0
Data variables:
tasmin (lat, time) float32 6kB dask.array<chunksize=(1, 730), meta=np.ndarray>
tasmax (lat, time) float32 6kB dask.array<chunksize=(1, 730), meta=np.ndarray>
pr (lat, time) float32 6kB dask.array<chunksize=(1, 730), meta=np.ndarray>
Attributes: (12/84)
Conventions: CF-1.7 CMIP-6.2
Notes: Regridded on the grid of ERA5-Land, then...
activity_id: CMIP
branch_method: standard
branch_time_in_child: 0.0
branch_time_in_parent: 21915.0
... ...
bias_adjust_reference_citation: https://doi.org/10.24381/cds.e2161bac
license_type: permissive
terms_of_use: In addition to the provided licence, the...
attribution: Use of this dataset should be acknowledg...
modeling_realm: atmos
source_institution: CSIRO[29]:
tasmin_nh = ds6.tasmin.sel(lat=slice(0, 90))
tasmin_sh = ds6.tasmin.sel(lat=slice(-90, 0))
[30]:
frost_days_nh = xclim.atmos.frost_days(tasmin_nh, freq=freq_nh)
frost_days_sh = xclim.atmos.frost_days(tasmin_sh, freq=freq_sh)
We have to handle both hemispheres separately since we get different time axes for each hemisphere.
[31]:
frost_days_nh.time
[31]:
<xarray.DataArray 'time' (time: 3)> Size: 24B
array([cftime.DatetimeNoLeap(1949, 7, 1, 0, 0, 0, 0, has_year_zero=True),
cftime.DatetimeNoLeap(1950, 7, 1, 0, 0, 0, 0, has_year_zero=True),
cftime.DatetimeNoLeap(1951, 7, 1, 0, 0, 0, 0, has_year_zero=True)],
dtype=object)
Coordinates:
* time (time) object 24B 1949-07-01 00:00:00 ... 1951-07-01 00:00:00
lon float32 4B -179.0[32]:
frost_days_sh.time
[32]:
<xarray.DataArray 'time' (time: 2)> Size: 16B
array([cftime.DatetimeNoLeap(1950, 1, 1, 0, 0, 0, 0, has_year_zero=True),
cftime.DatetimeNoLeap(1951, 1, 1, 0, 0, 0, 0, has_year_zero=True)],
dtype=object)
Coordinates:
* time (time) object 16B 1950-01-01 00:00:00 1951-01-01 00:00:00
lon float32 4B -179.0We could merge both datasets if we so wished, but that would require some arbitrary choice about which time axis to keep.
For example, if we decided the winter should be assigned to the year it ends on, we could do:
[33]:
frost_days_nh_fixed = frost_days_nh.isel(time=slice(0, -1)).assign_coords(time=frost_days_sh.time)
frost_days = xr.concat([frost_days_sh, frost_days_nh_fixed], "lat")
frost_days.time
[33]:
<xarray.DataArray 'time' (time: 2)> Size: 16B
array([cftime.DatetimeNoLeap(1950, 1, 1, 0, 0, 0, 0, has_year_zero=True),
cftime.DatetimeNoLeap(1951, 1, 1, 0, 0, 0, 0, has_year_zero=True)],
dtype=object)
Coordinates:
* time (time) object 16B 1950-01-01 00:00:00 1951-01-01 00:00:00
lon float32 4B -179.0So the code remained simple, this required us to drop the last element (winter 1952) which doesn’t exist in the southern hemisphere result. Instead of simply replacing the time coordinate, we could also explicitly “roll” the timestamps forward to the next starting point of the “YS” frequency (so the next january).
[34]:
YS = xr.coding.cftime_offsets.to_offset("YS")
new_time = frost_days_nh.indexes["time"].map(YS.rollforward)
frost_days_nh_fixed = frost_days_nh.assign_coords(time=new_time)
frost_days = xr.concat([frost_days_sh, frost_days_nh_fixed], "lat", join="outer")
frost_days.time
[34]:
<xarray.DataArray 'time' (time: 3)> Size: 24B
array([cftime.DatetimeNoLeap(1950, 1, 1, 0, 0, 0, 0, has_year_zero=True),
cftime.DatetimeNoLeap(1951, 1, 1, 0, 0, 0, 0, has_year_zero=True),
cftime.DatetimeNoLeap(1952, 1, 1, 0, 0, 0, 0, has_year_zero=True)],
dtype=object)
Coordinates:
* time (time) object 24B 1950-01-01 00:00:00 ... 1952-01-01 00:00:00
lon float32 4B -179.0