Download this notebook from github.
[1]:
# This cell is not visible when the documentation is built.
from __future__ import annotations
import numpy as np
import pandas as pd
import xarray as xr
from scipy.interpolate import interp1d
# Workaround for determining the notebook folder within a running notebook
try:
from _finder import _find_current_folder
notebook_folder = _find_current_folder()
except ImportError:
from pathlib import Path
notebook_folder = Path().cwd()
pd.plotting.register_matplotlib_converters()
data_folder = notebook_folder / "data"
data_folder.mkdir(exist_ok=True)
# time vector on 4 years
times = pd.date_range("2000-01-01", "2003-12-31", freq="D")
# temperature data as seasonal cycle -18 to 18
tas = xr.DataArray(
-18 * np.cos(2 * np.pi * times.dayofyear / 365),
dims=("time",),
coords={"time": times},
name="tas",
attrs={
"units": "degC",
"standard_name": "air_temperature",
"long_name": "Mean air temperature at surface",
},
)
# write 10 members adding cubic-smoothed gaussian noise of wave number 43 and amplitude 20
# resulting temp will oscillate between -18 and 38
for i in range(10):
tasi = tas + 20 * interp1d(np.arange(43), np.random.random((43,)), kind="quadratic")(np.linspace(0, 42, tas.size))
tasi.name = "tas"
tasi.attrs.update(tas.attrs)
tasi.attrs["title"] = f"tas of member {i:02d}"
tasi.to_netcdf(data_folder.joinpath(f"ens_tas_m{i}.nc"))
# Create 'toy' criteria selection data
np.random.normal(loc=3.5, scale=1.5, size=50)
# crit['delta_annual_tavg']
np.random.seed(0)
test = xr.DataArray(np.random.normal(loc=3, scale=1.5, size=100), dims=["realization"]).assign_coords(
horizon="2041-2070"
)
test = xr.concat(
(
test,
xr.DataArray(np.random.normal(loc=5.34, scale=2, size=100), dims=["realization"]).assign_coords(
horizon="2071-2100"
),
),
dim="horizon",
)
ds_crit = xr.Dataset()
ds_crit["delta_annual_tavg"] = test
test = xr.DataArray(np.random.normal(loc=5, scale=5, size=100), dims=["realization"]).assign_coords(horizon="2041-2070")
test = xr.concat(
(
test,
xr.DataArray(np.random.normal(loc=10, scale=8, size=100), dims=["realization"]).assign_coords(
horizon="2071-2100"
),
),
dim="horizon",
)
ds_crit["delta_annual_prtot"] = test
test = xr.DataArray(np.random.normal(loc=0, scale=3, size=100), dims=["realization"]).assign_coords(horizon="2041-2070")
test = xr.concat(
(
test,
xr.DataArray(np.random.normal(loc=2, scale=4, size=100), dims=["realization"]).assign_coords(
horizon="2071-2100"
),
),
dim="horizon",
)
ds_crit["delta_JJA_prtot"] = test
Ensembles¶
An important aspect of climate models is that they are run multiple times with some initial perturbations to see how they replicate the natural variability of the climate. Through xclim.ensembles, xclim provides an easy interface to compute ensemble statistics on different members. Most methods perform checks and conversion on top of simpler xarray methods, providing an easier interface to use.
create_ensemble¶
Our first step is to create an ensemble. This method takes a list of files defining the same variables over the same coordinates and concatenates them into one dataset with an added dimension realization.
Using xarray a very simple way of creating an ensemble dataset would be :
import xarray
xarray.open_mfdataset(files, concat_dim='realization')
However, this is only successful when the dimensions of all the files are identical AND only if the calendar type of each netcdf file is the same
xclim’s create_ensemble() method overcomes these constraints, selecting the common time period to all files and assigns a standard calendar type to the dataset.
Input netcdf files still require equal spatial dimension size (e.g. lon, lat dimensions).
Given files all named ens_tas_m[member number].nc, we use glob to get a list of all those files.
[2]:
import matplotlib as mpl
import matplotlib.pyplot as plt
import xarray as xr
from xclim import ensembles
# Set display to HTML style (for fancy output)
xr.set_options(display_style="html", display_width=50)
%matplotlib inline
ens = ensembles.create_ensemble(data_folder.glob("ens_tas_m*.nc")).load()
ens.close()
[3]:
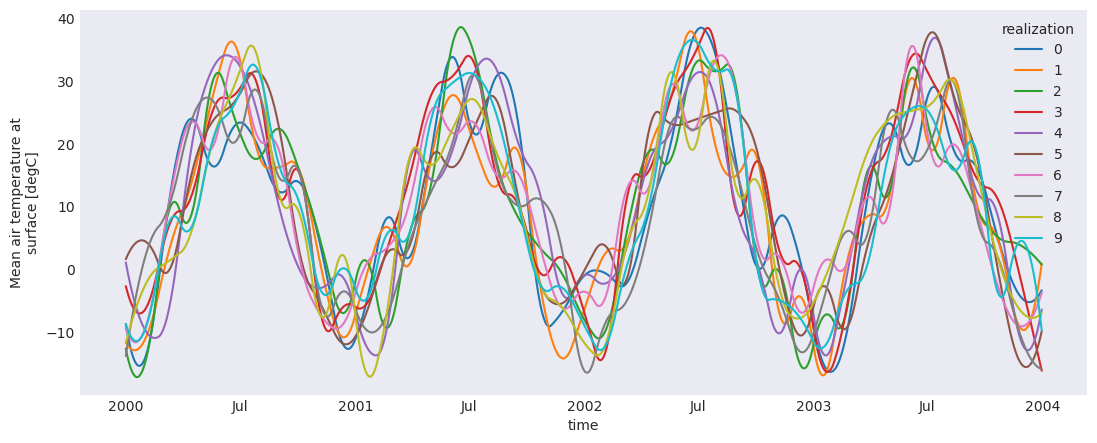
plt.style.use("seaborn-v0_8-dark")
plt.rcParams["figure.figsize"] = (13, 5)
ens.tas.plot(hue="realization")
plt.show()
[4]:
ens.tas # Attributes of the first dataset to be opened are copied to the final output
[4]:
<xarray.DataArray 'tas' (realization: 10,
time: 1461)> Size: 117kB
array([[ -6.99305501, -7.05764555, -7.11798815, ..., -9.37197873,
-9.18335896, -8.98229947],
[-12.17678179, -12.44634819, -12.69841108, ..., -16.40999576,
-16.6504312 , -16.88546336],
[ -7.37020569, -7.01344325, -6.66907168, ..., -7.1740622 ,
-7.75008265, -8.34245866],
...,
[-12.64382953, -12.25179616, -11.86104235, ..., -9.78096737,
-10.10148413, -10.42904503],
[-11.68304385, -11.43173508, -11.18442258, ..., -13.75999645,
-14.62949591, -15.52168949],
[-16.22188524, -15.99864981, -15.77549606, ..., -12.52048684,
-12.32357507, -12.1169032 ]], shape=(10, 1461))
Coordinates:
* realization (realization) int64 80B 0 1 ... 9
* time (time) datetime64[ns] 12kB 200...
Attributes:
units: degC
standard_name: air_temperature
long_name: Mean air temperature at sur...
title: tas of member 06Ensemble statistics¶
Beyond creating an ensemble dataset, the xclim.ensembles module contains functions for calculating statistics between realizations
Ensemble mean, standard-deviation, max & min
In the example below, we use xclim’s ensemble_mean_std_max_min() to calculate statistics across the 10 realizations in our test dataset. Output variables are created combining the original variable name tas with additional ending indicating the statistic calculated on the realization dimension : _mean, _stdev, _min, _max
The resulting output now contains 4 derived variables from the original single variable in our ensemble dataset.
[5]:
ens_stats = ensembles.ensemble_mean_std_max_min(ens)
ens_stats
[5]:
<xarray.Dataset> Size: 58kB
Dimensions: (time: 1461)
Coordinates:
* time (time) datetime64[ns] 12kB 2000-...
Data variables:
tas_mean (time) float64 12kB -8.513 ... -...
tas_stdev (time) float64 12kB 4.898 ... 3.511
tas_max (time) float64 12kB 0.7187 ... -...
tas_min (time) float64 12kB -16.22 ... -...
Attributes:
history: [2026-05-25 16:33:19] : Computati...Ensemble percentiles¶
Here, we use xclim’s ensemble_percentiles() to calculate percentile values across the 10 realizations. The output has now a percentiles dimension instead of realization. Split variables can be created instead, by specifying split=True (the variable name tas will be appended with _p{x}). Compared to NumPy’s percentile() and xarray’s quantile(), this method handles more efficiently dataset with invalid values and the chunking along the realization dimension (which
is automatic when dask arrays are used).
[6]:
ens_perc = ensembles.ensemble_percentiles(ens, values=[15, 50, 85], split=False)
ens_perc
[6]:
<xarray.Dataset> Size: 47kB
Dimensions: (time: 1461, percentiles: 3)
Coordinates:
* time (time) datetime64[ns] 12kB 200...
* percentiles (percentiles) int64 24B 15 50 85
Data variables:
tas (time, percentiles) float64 35kB ...
Attributes:
units: degC
standard_name: air_temperature
long_name: Mean air temperature at sur...
title: tas of member 06
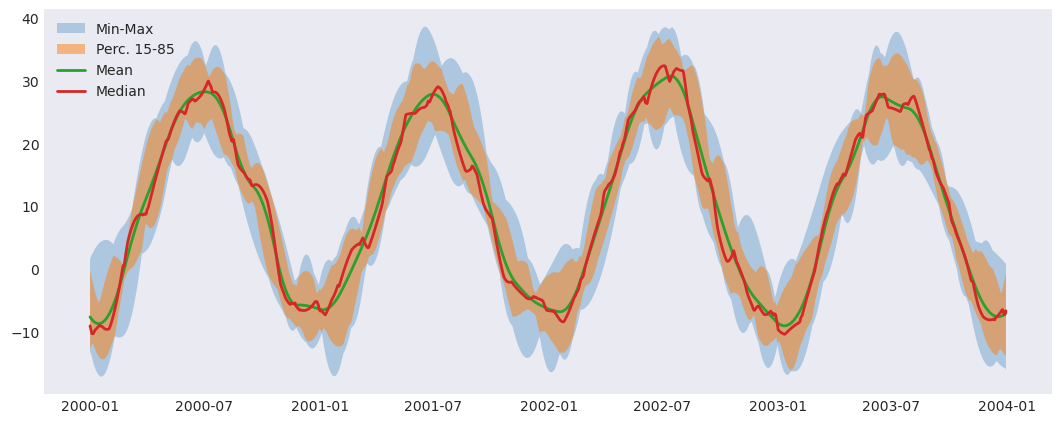
history: [2026-05-25 16:33:19] : Com...[7]:
fig, ax = plt.subplots()
ax.fill_between(
ens_stats.time.values,
ens_stats.tas_min,
ens_stats.tas_max,
alpha=0.3,
label="Min-Max",
)
ax.fill_between(
ens_perc.time.values,
ens_perc.tas.sel(percentiles=15),
ens_perc.tas.sel(percentiles=85),
alpha=0.5,
label="Perc. 15-85",
)
ax._get_lines.get_next_color() # Hack to get different line
ax._get_lines.get_next_color()
ax.plot(ens_stats.time.values, ens_stats.tas_mean, linewidth=2, label="Mean")
ax.plot(ens_perc.time.values, ens_perc.tas.sel(percentiles=50), linewidth=2, label="Median")
ax.legend()
plt.show()
Change significance and model agreement¶
When communicating climate change through plots of projected change, it is often useful to add information on the statistical significance of the values. A common way to represent this information without overloading the figures is through hatching patterns superimposed on the primary data. Two aspects are usually shown:
change significance: whether most of the ensemble members project a statistically significant climate change signal, in comparison to their internal variability.
model agreement: whether the different ensemble members agree on the sign of the change.
We can then divide the plotted points into categories each with its own hatching pattern, usually leaving the robust data (models agree and enough show a significant change) without hatching.
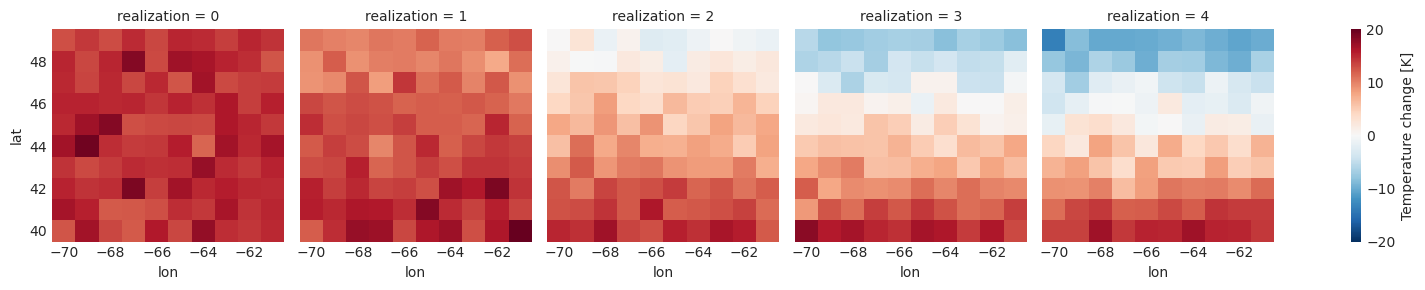
Xclim provides some tools to help in generating these hatching masks. First is xc.ensembles.robustness_fractions that can characterize the change significance and sign agreement across ensemble members. To demonstrate its usage, we’ll first generate some fake annual mean temperature data. Here, ref is the data on the reference period and fut is a future projection. There are five (5) different members in
the ensemble. We tweaked the generation so that all models agree on significant change in the “South” while agreement and significance of change decreases as we go North and East.
[8]:
import numpy as np
import xarray as xr
from matplotlib.patches import Rectangle
xr.set_options(keep_attrs=True)
# Reference period
ref = xr.DataArray(
20 * np.random.random_sample((5, 30, 10, 10)) + 275,
dims=("realization", "time", "lat", "lon"),
coords={
"time": xr.date_range("1990", periods=30, freq="YS"),
"lat": np.arange(40, 50),
"lon": np.arange(-70, -60),
},
attrs={"units": "K"},
)
# Future
fut = xr.DataArray(
20 * np.random.random_sample((5, 30, 10, 10)) + 275,
dims=("realization", "time", "lat", "lon"),
coords={
"time": xr.date_range("2070", periods=30, freq="YS"),
"lat": np.arange(40, 50),
"lon": np.arange(-70, -60),
},
attrs={"units": "K"},
)
# Add change.
fut = fut + xr.concat(
[xr.DataArray(np.linspace(15, north_delta, num=10), dims=("lat",)) for north_delta in [15, 10, 0, -7, -10]],
"realization",
)
deltas = (fut.mean("time") - ref.mean("time")).assign_attrs(long_name="Temperature change")
mean_delta = deltas.mean("realization")
deltas.plot(col="realization")
[8]:
<xarray.plot.facetgrid.FacetGrid at 0x747fdc2b6ba0>
Change significance can be determined in a lot of different ways. Xclim provides some simple and some more complicated statistical test in robustness_fractions. In this example, we’ll follow the suggestions found in the Cross-Chapter Box 1 of the IPCC Atlas chapter (AR6, WG1). Specifically, we are following Approach C, using the alternative for when pre-industrial control data is not available.
We first compute the different fractions for each robustness aspect.
[9]:
fractions = ensembles.robustness_fractions(fut, ref, test="ipcc-ar6-c")
fractions
[9]:
<xarray.Dataset> Size: 6kB
Dimensions: (lat: 10, lon: 10)
Coordinates:
* lat (lat) int64 80B 40 41 ... 49
* lon (lon) int64 80B -70 ... -61
Data variables:
changed (lat, lon) float64 800B 1...
positive (lat, lon) float64 800B 1...
changed_positive (lat, lon) float64 800B 1...
negative (lat, lon) float64 800B 0...
changed_negative (lat, lon) float64 800B 0...
valid (lat, lon) float64 800B 1...
agree (lat, lon) float64 800B 1...
Attributes:
description: Significant change and sign o...
history: [2026-05-25 16:33:20] : robus...In this output we have:
changed: The fraction of members showing significant change.positive: The fraction of members showing positive change, no matter if it is significant or not.changed_positive: The fraction of members showing significant AND positive change.agree: The fraction of members agreeing on the sign of change. This is the maximum betweenpositiveand1 - positive.valid: The fraction of “valid” members. A member is valid is there are no NaNs along the time axes offutandref. In our case, it is 1 everywhere.
For example, here’s the plot of the fraction of members showing significant change.
[10]:
fractions.changed.plot(figsize=(6, 4))
[10]:
<matplotlib.collections.QuadMesh at 0x747fcffb1490>
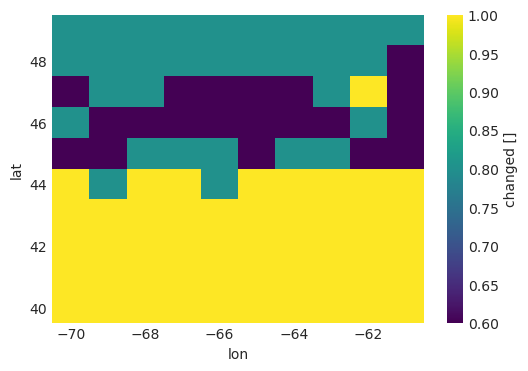
Xclim provides all this so that one can construct their own robustness maps the way they want. Often, hatching overlays are based on categories defined by some thresholds on the significant change and agreement fractions. The `xclim.ensembles.robustness_categories <../apidoc/xclim.ensembles.rst#xclim.ensembles._robustness.robustness_categories>`__ function helps for that common case and defaults to the categories and thresholds used by the IPCC in its Atlas.
[11]:
robustness = ensembles.robustness_categories(fractions)
robustness
[11]:
<xarray.DataArray (lat: 10, lon: 10)> Size: 800B
array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[2, 2, 1, 1, 1, 2, 1, 1, 2, 2],
[1, 2, 2, 2, 2, 2, 2, 2, 1, 2],
[2, 3, 3, 2, 2, 2, 2, 3, 3, 2],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 2],
[3, 3, 3, 3, 3, 3, 3, 3, 3, 3]])
Coordinates:
* lat (lat) int64 80B 40 41 42 ... 47 48 49
* lon (lon) int64 80B -70 -69 ... -62 -61
Attributes:
units:
description: Fraction of valid membe...
test: ipcc-ar6-c
flag_values: [1, 2, 3]
_FillValue: 99
flag_descriptions: ['Robust signal', 'No c...
flag_meanings: robust_signal no_change...The output is a categorical map following the “flag variables” CF conventions. Parameters needed for plotting are found in the attributes.
[12]:
robustness.plot(figsize=(6, 4))
[12]:
<matplotlib.collections.QuadMesh at 0x747fcfebf1d0>
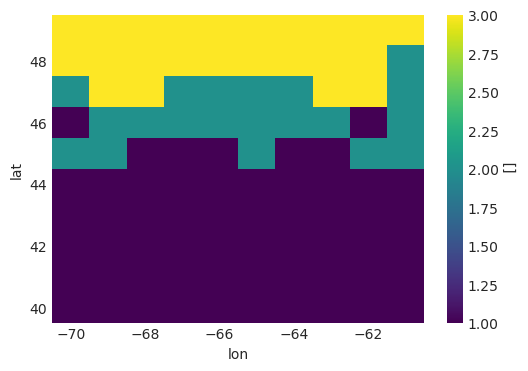
Matplotlib doesn’t provide an easy way of plotting categorial data with a proper legend, so our real plotting script is a bit more complicated, but xclim’s output makes it easier.
[13]:
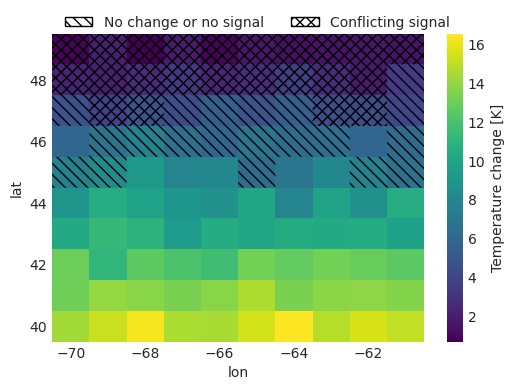
cmap = mpl.colors.ListedColormap(["none"]) # So we can deactivate pcolor's colormapping
fig, ax = plt.subplots(figsize=(6, 4))
mean_delta.plot(ax=ax)
# For each flag value plot the corresponding hatch.
for val, ha in zip(robustness.flag_values, [None, "\\\\\\", "xxx"], strict=False):
ax.pcolor(
robustness.lon,
robustness.lat,
robustness.where(robustness == val),
hatch=ha,
cmap=cmap,
)
ax.legend(
handles=[
Rectangle((0, 0), 2, 2, fill=False, hatch=h, label=lbl)
for h, lbl in zip(["\\\\\\", "xxx"], robustness.flag_descriptions[1:], strict=False)
],
bbox_to_anchor=(0.0, 1.1),
loc="upper left",
ncols=2,
);