Download this notebook from github.
Ensembles
An important aspect of climate models is that they are run multiple times with some initial perturbations to see how they replicate the natural variability of the climate. Through xclim.ensembles, xclim provides an easy interface to compute ensemble statistics on different members. Most methods perform checks and conversion on top of simpler xarray methods, providing an easier interface to use.
create_ensemble
Our first step is to create an ensemble. This methods takes a list of files defining the same variables over the same coordinates and concatenates them into one dataset with an added dimension realization.
Using xarray a very simple way of creating an ensemble dataset would be :
import xarray
xarray.open_mfdataset(files, concat_dim='realization')
However, this is only successful when the dimensions of all the files are identical AND only if the calendar type of each netcdf file is the same
xclim’s create_ensemble() method overcomes these constraints selecting the common time period to all files and assigns a standard calendar type to the dataset.
Input netcdf files still require equal spatial dimension size (e.g. lon, lat dimensions). If input data contains multiple cftime calendar types they must not be at daily frequency.
Given files all named ens_tas_m[member number].nc, we use glob to get a list of all those files.
[2]:
import glob
import xclim as xc
import xarray as xr
# Set display to HTML sytle (for fancy output)
xr.set_options(display_style='html', display_width=50)
import matplotlib.pyplot as plt
%matplotlib inline
from xclim import ensembles
ens = ensembles.create_ensemble(glob.glob('ens_tas_m*.nc')).load()
ens.close()
[3]:
plt.style.use('seaborn-dark')
plt.rcParams['figure.figsize'] = (13, 5)
ens.tas.plot(hue='realization')
plt.show()
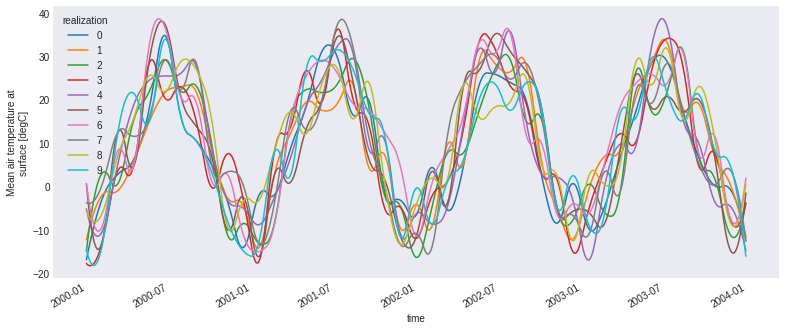
[4]:
ens.tas # Attributes of the first dataset to be opened are copied to the final output
[4]:
<xarray.DataArray 'tas' (realization: 10, time: 1461)>
array([[-16.89531376, -16.37804634, -15.86742294, ..., -10.71955895,
-11.1967711 , -11.6839108 ],
[-12.30676422, -11.85514754, -11.41257601, ..., -11.71199832,
-12.20664992, -12.7083277 ],
[-14.9283047 , -14.03619796, -13.16615392, ..., -5.06023441,
-4.50314791, -3.92378227],
...,
[ -3.76732693, -3.8232174 , -3.86848907, ..., -10.91462539,
-11.69800437, -12.50101669],
[ -5.63829167, -5.9087801 , -6.16411881, ..., -0.90048598,
-0.19486961, 0.53957563],
[-14.55033992, -14.98216613, -15.38665864, ..., -14.2795004 ,
-15.17376508, -16.08620306]])
Coordinates:
* time (time) datetime64[ns] 2000-01-...
* realization (realization) int64 0 1 2 ... 8 9
Attributes:
units: degC
standard_name: air_temperature
long_name: Mean air temperature at sur...
title: tas of member 05Ensemble statistics
Beyond creating ensemble dataset the xclim.ensembles module contains functions for calculating statistics between realizations
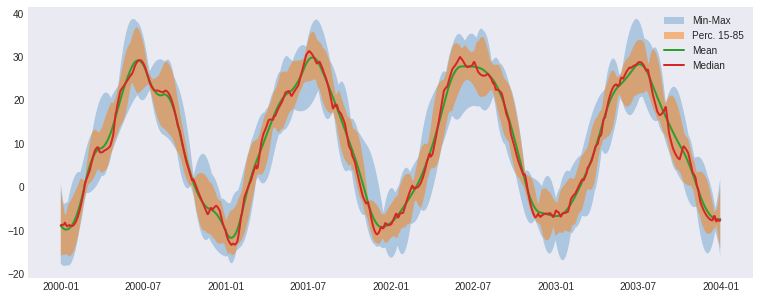
Ensemble mean, standard-deviation, max & min
In the example below we use xclim’s ensemble_mean_std_max_min() to calculate statistics across the 10 realizations in our test dataset. Output variables are created combining the original variable name tas with addtional ending indicating the statistic calculated on the realization dimension : _mean, _stdev, _min, _max
The resulting output now contains 4 derived variables from the original single variable in our ensemble dataset.
[5]:
ens_stats = ensembles.ensemble_mean_std_max_min(ens)
ens_stats
[5]:
<xarray.Dataset>
Dimensions: (time: 1461)
Coordinates:
* time (time) datetime64[ns] 2000-01-01...
Data variables:
tas_mean (time) float64 -8.97 ... -7.46
tas_stdev (time) float64 6.747 ... 6.419
tas_max (time) float64 0.6603 ... 1.881
tas_min (time) float64 -17.74 ... -16.09
Attributes:
history: [2022-01-10 15:39:17] : Computati...Ensemble percentiles
Here we use xclim’s ensemble_percentiles() to calculate percentile values across the 10 realizations. The output has now a percentiles dimension instead of realization. Split variables can be created instead, by specifying split=True (the variable name tas will be appended with _p{x}). Compared to numpy’s percentile() and xarray’s quantile(), this method handles more efficiently dataset with invalid values and the chunking along the realization dimension (which is
automatic when dask arrays are used).
[6]:
ens_perc = ensembles.ensemble_percentiles(ens, values=[15, 50, 85], split=False)
ens_perc
[6]:
<xarray.Dataset>
Dimensions: (time: 1461, percentiles: 3)
Coordinates:
* time (time) datetime64[ns] 2000-01-...
* percentiles (percentiles) int64 15 50 85
Data variables:
tas (time, percentiles) float64 -1...
Attributes:
units: degC
standard_name: air_temperature
long_name: Mean air temperature at sur...
title: tas of member 05
history: [2022-01-10 15:39:17] : Com...[7]:
fig, ax = plt.subplots()
ax.fill_between(ens_stats.time.values, ens_stats.tas_min, ens_stats.tas_max, alpha=0.3, label='Min-Max')
ax.fill_between(ens_perc.time.values, ens_perc.tas.sel(percentiles=15), ens_perc.tas.sel(percentiles=85), alpha=0.5, label='Perc. 15-85')
ax._get_lines.get_next_color() # Hack to get different line
ax._get_lines.get_next_color()
ax.plot(ens_stats.time.values, ens_stats.tas_mean, linewidth=2, label='Mean')
ax.plot(ens_perc.time.values, ens_perc.tas.sel(percentiles=50), linewidth=2, label='Median')
ax.legend()
plt.show()