Download this notebook from github.
Statistical Downscaling and Bias-Adjustment - Advanced tools
The previous notebook covered the most common utilities of xclim.sdba for conventional cases. Here, we explore more advanced usage of xclim.sdba tools.
Optimization with dask
Adjustment processes can be very heavy when we need to compute them over large regions and long timeseries. Using small groupings (like time.dayofyear) adds precision and robustness, but also decouples the load and computing complexity. Fortunately, unlike the heroic pioneers of scientific computing who managed to write parallelized FORTRAN, we now have dask. With only a few parameters, we can magically distribute the computing load to multiple workers and threads.
A good first read on the use of dask within xarray are the latter’s Optimization tips.
Some xclim.sdba-specific tips:
Most adjustment method will need to perform operation on the whole
timecoordinate, so it is best to optimize chunking along the other dimensions. This is often different from how public data is shared, where more universal 3D chunks are used.Chunking of outputs can be controlled in xarray’s to_netcdf. We also suggest using Zarr files. According to its creators,
zarrstores should give better performances, especially because of their better ability for parallel I/O. See Dataset.to_zarr and this useful rechunking package.One of the main bottleneck for adjustments with small groups is that dask needs to build and optimize an enormous task graph. This issue has been greatly reduced with xclim 0.27 and the use of
map_blocksin the adjustment methods. However, not all adjustment methods use this optimized syntax.In order to help dask, one can split the processing in parts. For splitting training and adjustment, see the section below.
Another massive bottleneck of parallelization of
xarrayis the thread-locking behaviour of some methods. It is quite difficult to isolate and avoid these locking instances, so one of the best workarounds is to usedaskconfigurations with many processes and few threads. The former do not share memory and thus are not impacted when a lock is activated from a thread in another worker. However, this adds many memory transfer operations and, by experience, reduces dask’s ability to parallelize some pipelines. Such a dask Client is usually created with a largen_workersand a smallthreads_per_worker.Sometimes, datasets have auxiliary coordinates (for example : lat / lon in a rotated pole dataset). Xarray handles these variables as data variables and will not load them if dask is used. However, in some operations,
xclimorxarraywill trigger access to those variables, triggering computations each time, since they aredask-based. To avoid this behaviour, one can load the coordinates, or simply remove them from the inputs.
LOESS smoothing and detrending
As described in Cleveland (1979), locally weighted linear regressions are multiple regression methods using a nearest-neighbour approach. Instead of using all data points to compute a linear or polynomial regression, LOESS algorithms compute a local regression for each point in the dataset, using only the k-nearest neighbours as selected by a weighting function. This weighting function must fulfill some strict requirements, see the doc of xclim.sdba.loess.loess_smoothing for more details.
In xclim’s implementation, the user can choose between local constancy (\(d=0\), local estimates are weighted averages) and local linearity (\(d=1\), local estimates are taken from linear regressions). Two weighting functions are currently implemented : “tricube” (\(w(x) = (1 - x^3)^3\)) and “gaussian” (\(w(x) = e^{-x^2 / 2\sigma^2}\)). Finally, the number of Cleveland’s robustifying iterations is controllable through niter. After computing an estimate of \(y(x)\),
the weights are modulated by a function of the distance between the estimate and the points and the procedure is started over. These iterations are made to weaken the effect of outliers on the estimate.
The next example shows the application of the LOESS to daily temperature data. The black line and dot are the estimated \(y\), outputs of the sdba.loess.loess_smoothing function, using local linear regression (passing \(d = 1\)), a window spanning 20% (\(f = 0.2\)) of the domain, the “tricube” weighting function and only one iteration. The red curve illustrates the weighting function on January 1st 2014, where the red circles are the nearest-neighbours used in the estimation.
[1]:
from __future__ import annotations
import matplotlib.pyplot as plt
import nc_time_axis
import numpy as np
import xarray as xr
from xclim.sdba import loess
%matplotlib inline
[2]:
# Daily temperature data from xarray's tutorials
ds = xr.tutorial.open_dataset("air_temperature").resample(time="D").mean()
tas = ds.isel(lat=0, lon=0).air
# Compute the smoothed series
f = 0.2
ys = loess.loess_smoothing(tas, d=1, weights="tricube", f=f, niter=1)
# Plot data points and smoothed series
fig, ax = plt.subplots()
ax.plot(tas.time, tas, "o", fillstyle="none")
ax.plot(tas.time, ys, "k")
ax.set_xlabel("Time")
ax.set_ylabel("Temperature [K]")
## The code below calls internal functions to demonstrate how the weights are computed.
# LOESS algorithms as implemented here use scaled coordinates.
x = tas.time
x = (x - x[0]) / (x[-1] - x[0])
xi = x[366]
ti = tas.time[366]
# Weighting function take the distance with all neighbors scaled by the r parameter as input
r = int(f * tas.time.size)
h = np.sort(np.abs(x - xi))[r]
weights = loess._tricube_weighting(np.abs(x - xi).values / h)
# Plot nearest neighbors and weighing function
wax = ax.twinx()
wax.plot(tas.time, weights, color="indianred")
ax.plot(
tas.time, tas.where(tas * weights > 0), "o", color="lightcoral", fillstyle="none"
)
ax.plot(ti, ys[366], "ko")
wax.set_ylabel("Weights")
plt.show()
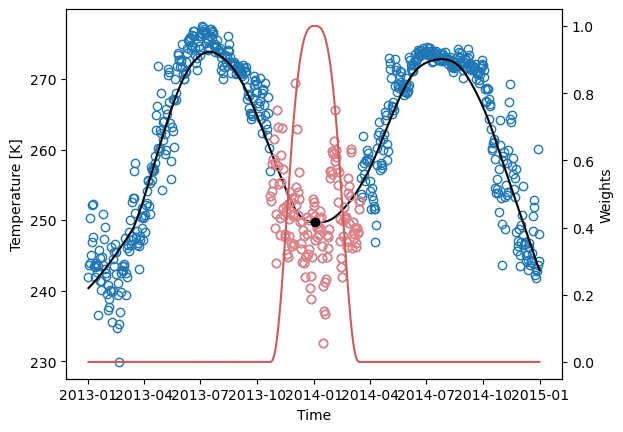
LOESS smoothing can suffer from heavy boundary effects. On the previous graph, we can associate the strange bend on the left end of the line to them. The next example shows a stronger case. Usually, \(\frac{f}{2}N\) points on each side should be discarded. On the other hand, LOESS has the advantage of always staying within the bounds of the data.
LOESS Detrending
In climate science, it can be used in the detrending process. xclim provides sdba.detrending.LoessDetrend in order to compute trend with the LOESS smoothing and remove them from timeseries.
First we create some toy data with a sinusoidal annual cycle, random noise and a linear temperature increase.
[3]:
time = xr.cftime_range("1990-01-01", "2049-12-31", calendar="noleap")
tas = xr.DataArray(
(
10 * np.sin(time.dayofyear * 2 * np.pi / 365)
+ 5 * (np.random.random_sample(time.size) - 0.5) # Annual variability
+ np.linspace(0, 1.5, num=time.size) # Random noise
), # 1.5 degC increase in 60 years
dims=("time",),
coords={"time": time},
attrs={"units": "degC"},
name="temperature",
)
tas.plot()
[3]:
[<matplotlib.lines.Line2D at 0x7feec4745640>]
Then we compute the trend on the data. Here, we compute on the whole timeseries (group='time') with the parameters suggested above.
[4]:
from xclim.sdba.detrending import LoessDetrend
# Create the detrending object
det = LoessDetrend(group="time", d=0, niter=2, f=0.2)
# Fitting returns a new object and computes the trend.
fit = det.fit(tas)
# Get the detrended series
tas_det = fit.detrend(tas)
[5]:
fig, ax = plt.subplots()
fit.ds.trend.plot(ax=ax, label="Computed trend")
ax.plot(time, np.linspace(0, 1.5, num=time.size), label="Expected tred")
ax.plot([time[0], time[int(0.1 * time.size)]], [0.4, 0.4], linewidth=6, color="gray")
ax.plot([time[-int(0.1 * time.size)], time[-1]], [1.1, 1.1], linewidth=6, color="gray")
ax.legend()
[5]:
<matplotlib.legend.Legend at 0x7feec4724bc0>
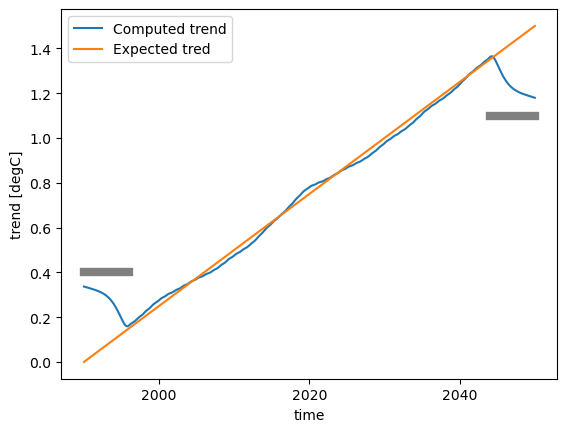
As said earlier, this example shows how the Loess has strong boundary effects. It is recommended to remove the \(\frac{f}{2}\cdot N\) outermost points on each side, as shown by the gray bars in the graph above.
Initializing an Adjustment object from a training dataset
For large scale uses, when the training step deserves its own computation and write to disk, or simply when there are multiples sim to be adjusted with the same training, it is helpful to be able to instantiate the Adjustment objects from the training dataset itself. This trick relies on a global attribute “adj_params” set on the training dataset.
[6]:
import numpy as np
import xarray as xr
# Create toy data for the example, here fake temperature timeseries
t = xr.cftime_range("2000-01-01", "2030-12-31", freq="D", calendar="noleap")
ref = xr.DataArray(
(
-20 * np.cos(2 * np.pi * t.dayofyear / 365)
+ 2 * np.random.random_sample((t.size,))
+ 273.15
+ 0.1 * (t - t[0]).days / 365
), # "warming" of 1K per decade,
dims=("time",),
coords={"time": t},
attrs={"units": "K"},
)
sim = xr.DataArray(
(
-18 * np.cos(2 * np.pi * t.dayofyear / 365)
+ 2 * np.random.random_sample((t.size,))
+ 273.15
+ 0.11 * (t - t[0]).days / 365
), # "warming" of 1.1K per decade
dims=("time",),
coords={"time": t},
attrs={"units": "K"},
)
ref = ref.sel(time=slice(None, "2015-01-01"))
hist = sim.sel(time=slice(None, "2015-01-01"))
[7]:
from xclim.sdba.adjustment import QuantileDeltaMapping
QDM = QuantileDeltaMapping.train(
ref, hist, nquantiles=15, kind="+", group="time.dayofyear"
)
QDM
[7]:
QuantileDeltaMapping(group=Grouper(name='time.dayofyear'), kind='+')
The trained QDM exposes the training data in the ds attribute, Here, we will write it to disk, read it back and initialize a new object from it. Notice the adj_params in the dataset, that has the same value as the repr string printed just above. Also, notice the _xclim_adjustment attribute that contains a JSON string, so we can rebuild the adjustment object later.
[8]:
QDM.ds
[8]:
<xarray.Dataset> Size: 91kB
Dimensions: (quantiles: 15, dayofyear: 365)
Coordinates:
* quantiles (quantiles) float64 120B 0.03333 0.1 0.1667 ... 0.8333 0.9 0.9667
* dayofyear (dayofyear) int64 3kB 1 2 3 4 5 6 7 ... 360 361 362 363 364 365
Data variables:
af (dayofyear, quantiles) float64 44kB -1.897 -2.096 ... -2.347
hist_q (dayofyear, quantiles) float64 44kB 255.7 256.1 ... 258.1 258.4
Attributes:
group: time.dayofyear
group_compute_dims: ['time']
group_window: 1
_xclim_adjustment: {"py/object": "xclim.sdba.adjustment.QuantileDeltaMa...
adj_params: QuantileDeltaMapping(group=Grouper(name='time.dayofy...[9]:
QDM.ds.to_netcdf("QDM_training.nc")
ds = xr.open_dataset("QDM_training.nc")
QDM2 = QuantileDeltaMapping.from_dataset(ds)
QDM2
[9]:
QuantileDeltaMapping(group=Grouper(name='time.dayofyear'), kind='+')
In the case above, creating a full object from the dataset doesn’t make the most sense since we are in the same python session, with the “old” object still available. This method effective when we reload the training data in a different python session, say on another computer. However, take note that there is no retro-compatibility insurance. If the QuantileDeltaMapping class was to change in a new xclim version, one would not be able to create the new object from a dataset saved with
the old one.
For the case where we stay in the same python session, it is still useful to trigger the dask computations. For small datasets, that could mean a simple QDM.ds.load(), but sometimes even the training data is too large to be full loaded in memory. In that case, we could also do:
[10]:
QDM.ds.to_netcdf("QDM_training2.nc")
ds = xr.open_dataset("QDM_training2.nc")
ds.attrs["title"] = "This is the dataset, but read from disk."
QDM.set_dataset(ds)
QDM.ds
[10]:
<xarray.Dataset> Size: 91kB
Dimensions: (quantiles: 15, dayofyear: 365)
Coordinates:
* quantiles (quantiles) float64 120B 0.03333 0.1 0.1667 ... 0.8333 0.9 0.9667
* dayofyear (dayofyear) int64 3kB 1 2 3 4 5 6 7 ... 360 361 362 363 364 365
Data variables:
af (dayofyear, quantiles) float64 44kB ...
hist_q (dayofyear, quantiles) float64 44kB ...
Attributes:
group: time.dayofyear
group_compute_dims: time
group_window: 1
_xclim_adjustment: {"py/object": "xclim.sdba.adjustment.QuantileDeltaMa...
adj_params: QuantileDeltaMapping(group=Grouper(name='time.dayofy...
title: This is the dataset, but read from disk.[11]:
QDM2.adjust(sim)
[11]:
<xarray.DataArray 'scen' (time: 11315)> Size: 91kB
array([254.36787962, 253.91450919, 253.96387129, ..., 258.39121189,
257.84387026, 256.85323826])
Coordinates:
* time (time) object 91kB 2000-01-01 00:00:00 ... 2030-12-31 00:00:00
Attributes:
units: K
history: [2024-02-27 17:45:18] : Bias-adjusted with QuantileDelt...
bias_adjustment: QuantileDeltaMapping(group=Grouper(name='time.dayofyear...Retrieving extra output diagnostics
To fully understand what is happening during the bias-adjustment process, sdba can output diagnostic variables, giving more visibility to what the adjustment is doing behind the scene. This behaviour, a verbose option, is controlled by the sdba_extra_output option, set with xclim.set_options. When True, train calls are instructed to include additional variables to the training datasets. In addition, the adjust calls will always output a dataset, with scen and,
depending on the algorithm, other diagnostics variables. See the documentation of each Adjustment objects to see what extra variables are available.
For the moment, this feature is still under construction and only a few Adjustment actually provide these extra outputs. Please open issues on the GitHub repo if you have needs or ideas of interesting diagnostic variables.
For example, QDM.adjust adds sim_q, which gives the quantile of each element of sim within its group.
[12]:
from xclim import set_options
with set_options(sdba_extra_output=True):
QDM = QuantileDeltaMapping.train(
ref, hist, nquantiles=15, kind="+", group="time.dayofyear"
)
out = QDM.adjust(sim)
out.sim_q
[12]:
<xarray.DataArray 'sim_q' (time: 11315)> Size: 91kB
array([0.13333333, 0.03333333, 0.1 , ..., 1. , 0.93333333,
0.9 ])
Coordinates:
* time (time) object 91kB 2000-01-01 00:00:00 ... 2030-12-31 00:00:00
Attributes:
group: time.dayofyear
group_compute_dims: time
group_window: 1
long_name: Group-wise quantiles of `sim`.Moving window for adjustments
Some Adjustment methods require that the adjusted data (sim) be of the same length (same number of points) than the training data (ref and hist). These requirements often ensure conservation of statistical properties and a better representation of the climate change signal over the long adjusted timeseries.
In opposition to a conventional “rolling window”, here it is the years that are the base units of the window, not the elements themselves. xclim implements xc.core.calendar.stack_periods and xc.core.calendar.unstack_periods to manipulate data in that goal. The “stack” function cuts the data in overlapping windows of a certain length and stacks them along a new "period" dimension, alike to xarray’s da.rolling(time=win).construct('period'), but with yearly steps. The stride
(or step) between each window can also be controlled. This argument is an indicator of how many years overlap between each window. With a value of 1, a window will have window - 1 years overlapping with the previous one. The default (None) is to have stride = window will result in no overlap at all. The default units in which window and stride are given is a year (“YS”), but can be changed with argument freq.
By chunking the result along this 'period' dimension, it is expected to be more computationally efficient (when using dask) than looping over the windows with a for-loop (or a GroupyBy)
Note that this results in two restrictions:
The constructed array has the same “time” axis for all windows. This is a problem if the actual year is of importance for the adjustment, but this is not the case for any of xclim’s current adjustment methods.
The input timeseries must be in a calendar with uniform year lengths. For daily data, this means only the “360_day”, “noleap” and “all_leap” calendars are supported.
The “unstack” function does the opposite : it concatenates the windows together to recreate the original timeseries. It only works for the no-overlap case where stride = window and for the non-ambiguous one where stride divides window into an odd number (N) of parts. In that latter situation, the middle parts of each period are kept when reconstructing the timeseries, in addition to the first (last) parts of the first (last) period needed to get a full timeseries.
Quantile Delta Mapping requires that the adjustment period should be of a length similar to the training one. As our ref and hist cover 15 years but sim covers 31 years, we will transform sim by stacking windows of 15 years. With a stride of 5 years, this means the first window goes from 2000 to 2014 (inclusive). Then 2005-2019, 2010-2024 and 2015-2029. The last year will be dropped as it can’t be included in any complete window.
In the following example, QDM is configurated with group="time.dayofyear" which will perform the adjustment for each day of year (doy) separately. When using stack_periods the extracted windows are all concatenated along the new period axis and they all share the same time coordinate. As such, for the doy information to make sense, we must use a calendar with uniform year lengths. Otherwise, the doys would shift one day at each leap year.
[13]:
QDM = QuantileDeltaMapping.train(
ref, hist, nquantiles=15, kind="+", group="time.dayofyear"
)
scen_nowin = QDM.adjust(sim)
[14]:
from xclim.core.calendar import stack_periods, unstack_periods
sim_win = stack_periods(sim, window=15, stride=5)
sim_win
[14]:
<xarray.DataArray (period: 4, time: 5475)> Size: 175kB
array([[256.46401116, 256.33753072, 256.04379492, ..., 257.38540365,
257.30418939, 258.39621904],
[257.34064248, 256.46240623, 257.6382671 , ..., 257.86650213,
257.42888523, 258.83742605],
[258.05213567, 257.55577571, 257.53641474, ..., 258.855895 ,
258.46072422, 258.21778336],
[257.85632549, 258.69828159, 258.70764299, ..., 259.38187059,
260.44421494, 258.84312381]])
Coordinates:
* time (time) object 44kB 1970-01-01 00:00:00 ... 1984-12-31 00:0...
period_length (period) int64 32B 5475 5475 5475 5475
* period (period) object 32B 2000-01-01 00:00:00 ... 2015-01-01 00:...
Attributes:
units: KHere, we retrieve the full timeseries (minus the lasy year that couldn’t fit in any window).
[15]:
scen_win = unstack_periods(QDM.adjust(sim_win))
scen_win
[15]:
<xarray.DataArray 'scen' (time: 10950)> Size: 88kB
array([254.18931599, 254.26081535, 253.88113194, ..., 257.45635576,
258.8832695 , 256.89626343])
Coordinates:
* time (time) object 88kB 2000-01-01 00:00:00 ... 2029-12-31 00:00:00
Attributes:
units: K
history: [2024-02-27 17:45:24] : Bias-adjusted with QuantileDelt...
bias_adjustment: QuantileDeltaMapping(group=Grouper(name='time.dayofyear...Full example: Multivariate adjustment in the additive space
The following example shows a complete bias-adjustment workflow using the PrincipalComponents method in a multi-variate configuration. Moreover, it uses the trick showed by Alavoine et Grenier (2022) to transform “multiplicative” variable to the “additive” space using log and logit transformations. This way, we can perform multi-variate adjustment with variables that couldn’t be used in the same kind of adjustment, like “tas” and “hurs”.
We will transform the variables that need it to the additive space, adding some jitter in the process to avoid \(log(0)\) situations. Then, we will stack the different variables into a single DataArray, allowing us to use PrincipalComponents in a multi-variate way. Following the PCA, a simple quantile-mapping method is used, both adjustment acting on the residuals, while the mean of the simulated trend is adjusted on its own. Each step will be explained.
First, open the data, convert the calendar and the units. Because we will perform adjustments on “dayofyear” groups (with a window), keeping standard calendars results in an extra “dayofyear” with only a quarter of the data. It’s usual to transform to a “noleap” calendar, which drops the 29th of February, as it only has a small impact on the data.
[16]:
import xclim.sdba as sdba
from xclim.core.calendar import convert_calendar
from xclim.core.units import convert_units_to
from xclim.testing import open_dataset
group = sdba.Grouper("time.dayofyear", window=31)
dref = convert_calendar(open_dataset("sdba/ahccd_1950-2013.nc"), "noleap").sel(
time=slice("1981", "2010")
)
dsim = open_dataset("sdba/CanESM2_1950-2100.nc")
dref = dref.assign(
tasmax=convert_units_to(dref.tasmax, "K"),
)
dsim = dsim.assign(pr=convert_units_to(dsim.pr, "mm/d"))
1. Jitter, additive space transformation and variable stacking
Here, tasmax is already ready to be adjusted in an additive way, because all data points are far from the physical zero (0 K). This is not the case for pr, which is why we want to transform that variable to the additive space, to avoid splitting our workflow in two. For pr the “log” transformation is simply:
Where \(b\) is the lower bound, here 0 mm/d. However, we could have exact zeros (0 mm/d) in the datasets, which will translate into \(-\infty\). To avoid this, we simply replace the smallest values by a random distribution of very small, but not problematic, values. In the following, all values below 0.1 mm/d are replaced by a uniform random distribution of values within the range (0, 0.1) mm/d (bounds excluded).
Finally, the variables are stacked together into a single DataArray.
[17]:
dref_as = dref.assign(
pr=sdba.processing.to_additive_space(
sdba.processing.jitter(dref.pr, lower="0.1 mm/d", minimum="0 mm/d"),
lower_bound="0 mm/d",
trans="log",
)
)
ref = sdba.stack_variables(dref_as)
dsim_as = dsim.assign(
pr=sdba.processing.to_additive_space(
sdba.processing.jitter(dsim.pr, lower="0.1 mm/d", minimum="0 mm/d"),
lower_bound="0 mm/d",
trans="log",
)
)
sim = sdba.stack_variables(dsim_as)
sim
[17]:
<xarray.DataArray 'multivariate' (multivar: 2, time: 55115, location: 3)> Size: 1MB
array([[[ 2.4951424e-01, -8.2575518e-01, 2.4951424e-01],
[ 2.6499709e-01, -4.1112199e-01, 2.6499709e-01],
[-1.9535354e-01, -2.4970021e+00, -1.9535354e-01],
...,
[ 3.2132244e+00, -2.2834629e-01, 3.2132244e+00],
[ 1.6713389e+00, 1.7489431e+00, 1.6713389e+00],
[ 7.5195450e-01, 2.4332018e+00, 7.5195450e-01]],
[[ 2.7815024e+02, 2.7754898e+02, 2.7815024e+02],
[ 2.8335815e+02, 2.7690921e+02, 2.8335815e+02],
[ 2.8153192e+02, 2.7668036e+02, 2.8153192e+02],
...,
[ 2.8901334e+02, 2.8192789e+02, 2.8901334e+02],
[ 2.8510699e+02, 2.8142294e+02, 2.8510699e+02],
[ 2.8404471e+02, 2.8160156e+02, 2.8404471e+02]]], dtype=float32)
Coordinates:
* time (time) object 441kB 1950-01-01 00:00:00 ... 2100-12-31 00:00:00
lat (location) float64 24B 49.1 67.8 48.8
lon (location) float64 24B -123.1 -115.1 -78.2
* location (location) <U9 108B 'Vancouver' 'Kugluktuk' 'Amos'
* multivar (multivar) <U6 48B 'pr' 'tasmax'
Attributes: (12/34)
institution: CanESM2
institute_id: CCCma
experiment_id: rcp85
source: CanESM2 2010 atmosphere: CanAM4 (AGCM15i...
model_id: CanESM2
forcing: GHG,Oz,SA,BC,OC,LU,Sl (GHG includes CO2,...
... ...
modeling_realm: atmos
realization: 1
cmor_version: 2.5.4
DODS_EXTRA.Unlimited_Dimension: time
description: Extracted from CMIP5 CanESM2 hist+rcp85 ...
units: 2. Get residuals and trends
The adjustment will be performed on residuals only. The adjusted timeseries sim will be detrended with the LOESS routine described above. Because of the short length of ref and hist and the potential boundary effects of using LOESS with them, we compute the 30-year mean. In other words, instead of detrending inputs, we are normalizing those inputs.
While the residuals are adjusted with PrincipalComponents and EmpiricalQuantileMapping, the trend of sim still needs to be offset according to the means of ref and hist. This is similar to what DetrendedQuantileMapping does. The offset step could have been done on the trend itself or at the end on scen, it doesn’t really matter. We do it here because it keeps it close to where the scaling is computed.
[18]:
ref_res, ref_norm = sdba.processing.normalize(ref, group=group, kind="+")
hist_res, hist_norm = sdba.processing.normalize(
sim.sel(time=slice("1981", "2010")), group=group, kind="+"
)
scaling = sdba.utils.get_correction(hist_norm, ref_norm, kind="+")
[19]:
sim_scaled = sdba.utils.apply_correction(
sim, sdba.utils.broadcast(scaling, sim, group=group), kind="+"
)
loess = sdba.detrending.LoessDetrend(group=group, f=0.2, d=0, kind="+", niter=1)
simfit = loess.fit(sim_scaled)
sim_res = simfit.detrend(sim_scaled)
3. Adjustments
Following, Alavoine et Grenier (2022), we decided to perform the multivariate Principal Components adjustment first and then re-adjust with the simple Quantile-Mapping.
[20]:
PCA = sdba.adjustment.PrincipalComponents.train(
ref_res, hist_res, group=group, crd_dim="multivar", best_orientation="simple"
)
scen1_res = PCA.adjust(sim_res)
[21]:
EQM = sdba.adjustment.EmpiricalQuantileMapping.train(
ref_res,
scen1_res.sel(time=slice("1981", "2010")),
group=group,
nquantiles=50,
kind="+",
)
scen2_res = EQM.adjust(scen1_res, interp="linear", extrapolation="constant")
4. Re-trend and transform back to the physical space
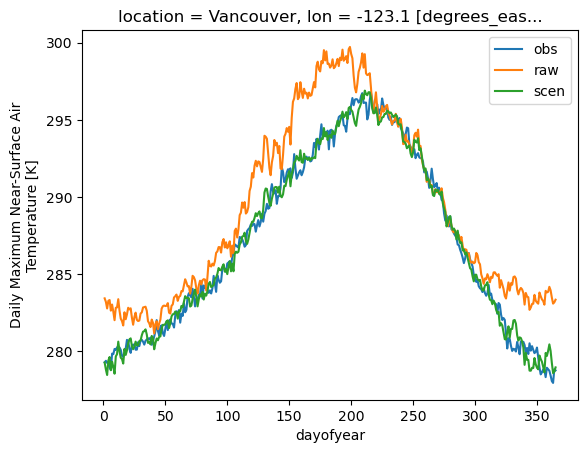
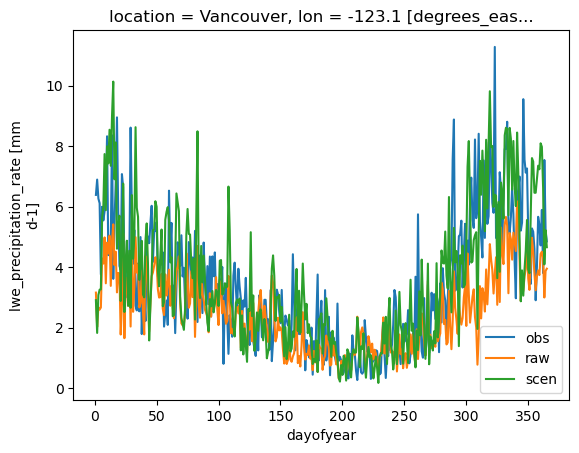
Add back the trend (which includes the scaling), unstack the variables to a dataset and transform pr back to the physical space. All functions have conserved and handled the attributes, so we don’t need to repeat the additive space bounds. The annual cycle of both variables on the reference period in Vancouver is plotted to confirm the adjustment adds a positive effect.
[22]:
scen = simfit.retrend(scen2_res)
dscen_as = sdba.unstack_variables(scen)
dscen = dscen_as.assign(pr=sdba.processing.from_additive_space(dscen_as.pr))
[23]:
dref.tasmax.sel(time=slice("1981", "2010"), location="Vancouver").groupby(
"time.dayofyear"
).mean().plot(label="obs")
dsim.tasmax.sel(time=slice("1981", "2010"), location="Vancouver").groupby(
"time.dayofyear"
).mean().plot(label="raw")
dscen.tasmax.sel(time=slice("1981", "2010"), location="Vancouver").groupby(
"time.dayofyear"
).mean().plot(label="scen")
plt.legend()
[23]:
<matplotlib.legend.Legend at 0x7feeb9f78e90>
[24]:
dref.pr.sel(time=slice("1981", "2010"), location="Vancouver").groupby(
"time.dayofyear"
).mean().plot(label="obs")
dsim.pr.sel(time=slice("1981", "2010"), location="Vancouver").groupby(
"time.dayofyear"
).mean().plot(label="raw")
dscen.pr.sel(time=slice("1981", "2010"), location="Vancouver").groupby(
"time.dayofyear"
).mean().plot(label="scen")
plt.legend()
[24]:
<matplotlib.legend.Legend at 0x7feeb933cf80>
Frequency adaption with a rolling window
In the previous example, we performed bias adjustment with a rolling window. Here we show how to include frequency adaptation (see sdba.ipynb for the simple case group="time"). We first generate the same precipitation dataset used in sdba.ipynb
[25]:
import numpy as np
import xarray as xr
t = xr.cftime_range("2000-01-01", "2030-12-31", freq="D", calendar="noleap")
vals = np.random.randint(0, 1000, size=(t.size,)) / 100
vals_ref = (4 ** np.where(vals < 9, vals / 100, vals)) / 3e6
vals_sim = (
(1 + 0.1 * np.random.random_sample((t.size,)))
* (4 ** np.where(vals < 9.5, vals / 100, vals))
/ 3e6
)
pr_ref = xr.DataArray(
vals_ref, coords={"time": t}, dims=("time",), attrs={"units": "mm/day"}
)
pr_ref = pr_ref.sel(time=slice("2000", "2015"))
pr_sim = xr.DataArray(
vals_sim, coords={"time": t}, dims=("time",), attrs={"units": "mm/day"}
)
pr_hist = pr_sim.sel(time=slice("2000", "2015"))
Bias adjustment on a rolling window can be performed in the same way as shown in sdba.ipynb, but instead of being a single string precising the time grouping (e.g. time.month), the group argument is built with sdba.Grouper function
[26]:
import matplotlib.pyplot as plt
# adapt_freq with a sdba.Grouper
from xclim import sdba
group = sdba.Grouper("time.dayofyear", window=31)
sim_ad, pth, dP0 = sdba.processing.adapt_freq(
pr_ref, pr_sim, thresh="0.05 mm d-1", group=group
)
QM_ad = sdba.EmpiricalQuantileMapping.train(
pr_ref, sim_ad, nquantiles=15, kind="*", group=group
)
scen_ad = QM_ad.adjust(pr_sim)
pr_ref.sel(time="2010").plot(alpha=0.9, label="Reference")
pr_sim.sel(time="2010").plot(alpha=0.7, label="Model - biased")
scen_ad.sel(time="2010").plot(alpha=0.6, label="Model - adjusted")
plt.legend()
[26]:
<matplotlib.legend.Legend at 0x7feec4616180>
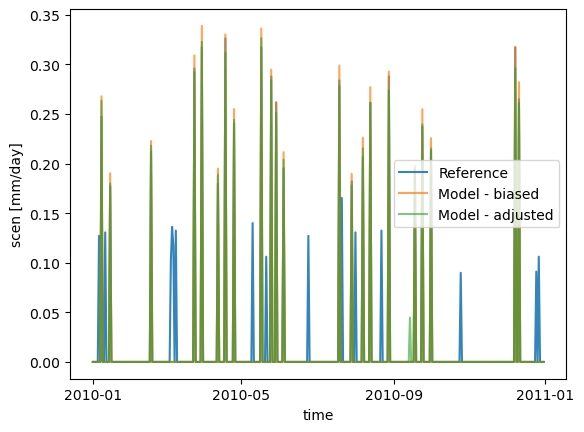
In the figure above, scen occasionally has small peaks where sim is 0, indicating that there are more “dry days” (days with almost no precipitation) in hist than in ref. The frequency-adaptation Themeßl et al. (2010) performed in the step above only worked partially.
The reason for this is the following. The first step above combines precipitations in 365 overlapping blocks of 31 days * Y years, one block for each day of the year. Each block is adapted, and the 16th day-of-year slice (at the center of the block) is assigned to the corresponding day-of-year in the adapted dataset sim_ad. As we proceed to the training, we re-form those 31 days * Y years blocks, but this step does not invert the last one: There can still be more zeroes in the simulation
than in the reference.
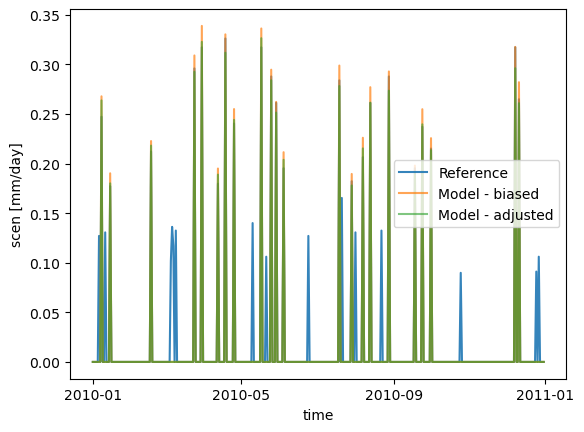
To alleviate this issue, another way of proceeding is to perform a frequency adaptation on the blocks, and then use the same blocks in the training step, as we show below.
[27]:
# adapt_freq directly in the training step
group = sdba.Grouper("time.dayofyear", window=31)
QM_ad = sdba.EmpiricalQuantileMapping.train(
pr_ref,
sim_ad,
nquantiles=15,
kind="*",
group=group,
adapt_freq_thresh="0.05 mm d-1",
)
scen_ad = QM_ad.adjust(pr_sim)
pr_ref.sel(time="2010").plot(alpha=0.9, label="Reference")
pr_sim.sel(time="2010").plot(alpha=0.7, label="Model - biased")
scen_ad.sel(time="2010").plot(alpha=0.6, label="Model - adjusted")
plt.legend()
[27]:
<matplotlib.legend.Legend at 0x7feec42a5280>
Tests for sdba
It can be useful to perform diagnostic tests on adjusted simulations to assess if the bias correction method is working properly, or to compare two different bias correction techniques.
A diagnostic test includes calculations of a property (mean, 20-year return value, annual cycle amplitude, …) on the simulation and on the scenario (adjusted simulation), then a measure (bias, relative bias, ratio, …) of the difference. Usually, the property collapse the time dimension of the simulation/scenario and returns one value by grid point.
You’ll find those in xclim.sdba.properties and xclim.sdba.measures, where they are implemented as special subclasses of xclim’s Indicator, which means they can be worked with the same way as conventional indicators (used in YAML modules for example).
[28]:
from matplotlib import pyplot as plt
import xclim as xc
from xclim import sdba
from xclim.testing import open_dataset
# load test data
hist = open_dataset("sdba/CanESM2_1950-2100.nc").sel(time=slice("1950", "1980")).tasmax
ref = open_dataset("sdba/nrcan_1950-2013.nc").sel(time=slice("1950", "1980")).tasmax
sim = (
open_dataset("sdba/CanESM2_1950-2100.nc").sel(time=slice("1980", "2010")).tasmax
) # biased
# learn the bias in historical simulation compared to reference
QM = sdba.EmpiricalQuantileMapping.train(
ref, hist, nquantiles=50, group="time", kind="+"
)
# correct the bias in the future
scen = QM.adjust(sim, extrapolation="constant", interp="nearest")
ref_future = (
open_dataset("sdba/nrcan_1950-2013.nc").sel(time=slice("1980", "2010")).tasmax
) # truth
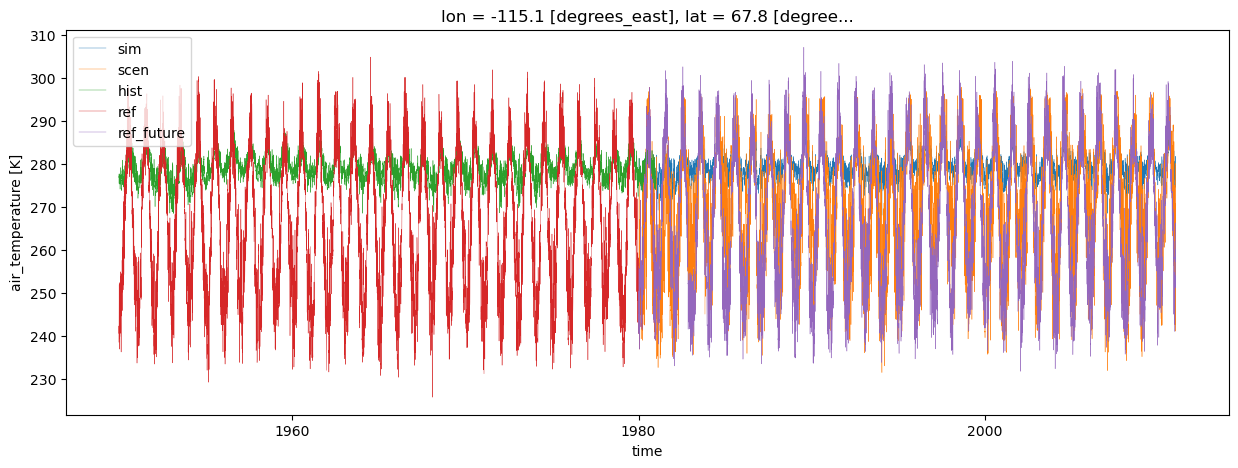
plt.figure(figsize=(15, 5))
lw = 0.3
sim.isel(location=1).plot(label="sim", linewidth=lw)
scen.isel(location=1).plot(label="scen", linewidth=lw)
hist.isel(location=1).plot(label="hist", linewidth=lw)
ref.isel(location=1).plot(label="ref", linewidth=lw)
ref_future.isel(location=1).plot(label="ref_future", linewidth=lw)
leg = plt.legend()
[29]:
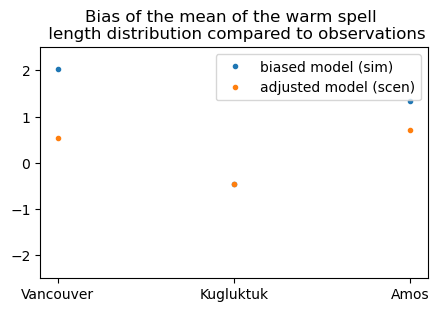
# calculate the mean warm Spell Length Distribution
sim_prop = sdba.properties.spell_length_distribution(
da=sim, thresh="28 degC", op=">", stat="mean", group="time"
)
scen_prop = sdba.properties.spell_length_distribution(
da=scen, thresh="28 degC", op=">", stat="mean", group="time"
)
ref_prop = sdba.properties.spell_length_distribution(
da=ref_future, thresh="28 degC", op=">", stat="mean", group="time"
)
# measure the difference between the prediction and the reference with an absolute bias of the properties
measure_sim = sdba.measures.bias(sim_prop, ref_prop)
measure_scen = sdba.measures.bias(scen_prop, ref_prop)
plt.figure(figsize=(5, 3))
plt.plot(measure_sim.location, measure_sim.values, ".", label="biased model (sim)")
plt.plot(measure_scen.location, measure_scen.values, ".", label="adjusted model (scen)")
plt.title(
"Bias of the mean of the warm spell \n length distribution compared to observations"
)
plt.legend()
plt.ylim(-2.5, 2.5)
[29]:
(-2.5, 2.5)
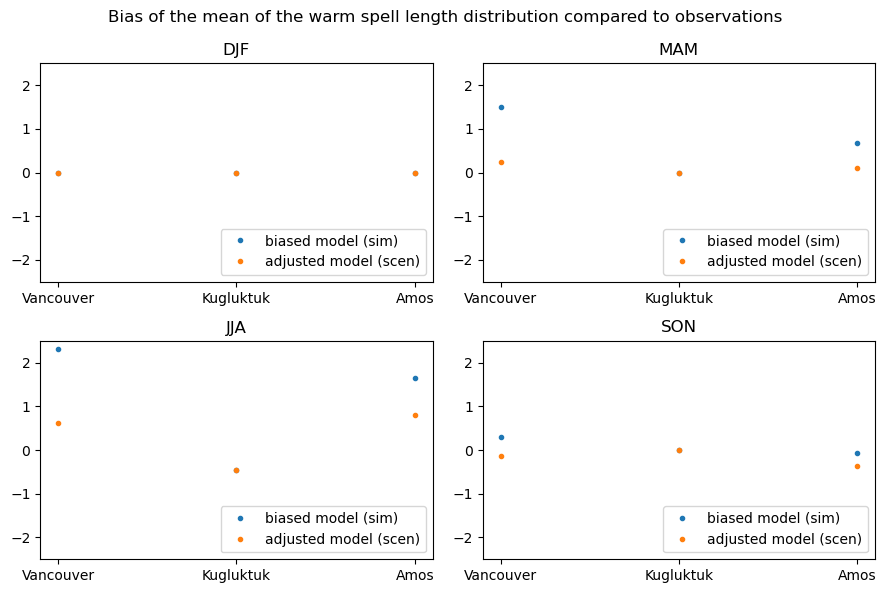
It is possible the change the ‘group’ of the property from ‘time’ to ‘time.season’ or ‘time.month’. This will return 4 or 12 values per grid point, respectively.
[30]:
# calculate the mean warm Spell Length Distribution
sim_prop = sdba.properties.spell_length_distribution(
da=sim, thresh="28 degC", op=">", stat="mean", group="time.season"
)
scen_prop = sdba.properties.spell_length_distribution(
da=scen, thresh="28 degC", op=">", stat="mean", group="time.season"
)
ref_prop = sdba.properties.spell_length_distribution(
da=ref_future, thresh="28 degC", op=">", stat="mean", group="time.season"
)
# Properties are often associated with the same measures. This correspondence is implemented in xclim:
measure = sdba.properties.spell_length_distribution.get_measure()
measure_sim = measure(sim_prop, ref_prop)
measure_scen = measure(scen_prop, ref_prop)
fig, axs = plt.subplots(2, 2, figsize=(9, 6))
axs = axs.ravel()
for i in range(4):
axs[i].plot(
measure_sim.location, measure_sim.values[:, i], ".", label="biased model (sim)"
)
axs[i].plot(
measure_scen.location,
measure_scen.isel(season=i).values,
".",
label="adjusted model (scen)",
)
axs[i].set_title(measure_scen.season.values[i])
axs[i].legend(loc="lower right")
axs[i].set_ylim(-2.5, 2.5)
fig.suptitle(
"Bias of the mean of the warm spell length distribution compared to observations"
)
plt.tight_layout()